2026年7月5日
从 Jekyll 到 Astro:个人技术博客的迁移实录
Jekyll 博客迁移至 Astro 5 的完整记录。
Android 应用层 · 智能座舱 · 移动端 AI
聚焦 Android 应用层与移动端 AI,曾参与智能座舱车控 IVI 系统研发,现探索 AI 原生个人记忆与效率应用。本站汇集跨车载与消费级场景的工程实践、架构洞察,以及对智能化交互演进的前瞻思考。
2026年7月5日
Jekyll 博客迁移至 Astro 5 的完整记录。
2026年7月6日
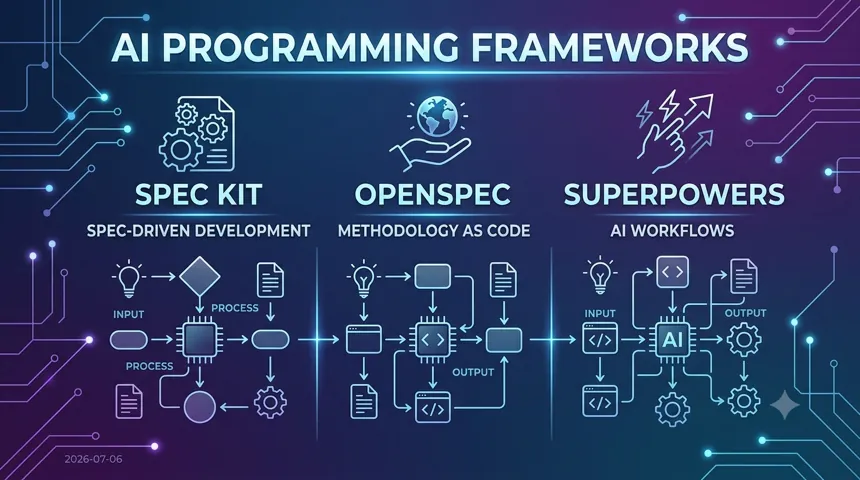
拆解三种 AI 编程框架的设计哲学与工作流。

2026年7月1日
Vibe Coding氛围感编程入门指南

2026年6月30日
Harness Engineering智能体工程化
2026年6月16日
Claude Code规则机制与提效指南
全球最大代码托管平台,开源协作与版本控制的入口。
Python 语言官方站点,文档、下载与生态资源入口。
Android 官方开发者文档,涵盖应用开发基础与系统 API 参考。
Kotlin 跨平台 UI 框架,一套 Compose 代码覆盖 Android、Desktop 与 Web。
Kotlin 语言官方站点,文档、Playground 与生态资源入口。
开源模型与数据集社区,预训练模型下载与推理部署的起点。
Google 端侧 AI 开发文档,LiteRT / Edge AI 等移动端部署方案。
DeepSeek 大模型官方站点,模型发布与 API 服务信息。
Google Gemini 多模态 AI 助手,对话、创作与开发集成入口。
改变一切的 Transformer 架构(2017)。
开启大模型 Few-shot 范式的 GPT-3 论文(2020)。
OpenAI 提出神经网络缩放定律,奠定大模型工程基调(2020)。
InstructGPT / RLHF 奠基论文,对齐人类偏好的起点(2022)。
开启慢思考 / 推理时代的技术研究发布页。
Anthropic 宪政 AI 论文,用 AI 反馈约束模型行为(2022)。
从 Claude 3 Sonnet 中提取可解释特征,神经网络黑盒破解(2024)。
极致 MoE 架构的开源大模型技术报告(2024)。
以强化学习激发 LLM 推理能力的开源推理神作(2025)。
Google 引入物理世界规则的统一设计语言,重塑生态审美(2014)。
Android 开发编码范式从 Java 迈向现代 Kotlin 的历史节点(2017)。
Jetpack 与官方架构指南,一统 Android 应用架构江湖(2018)。
声明式 UI 正式登场,终结沿用十几年的 XML 布局时代(2021)。
从 Android 1.0 到端侧 LLM 标配的系统级演进全程(2025-2026)。