【通用开发】JVM原理概要

本文介绍了JVM的运行原理,包括编译器和解释器的区别,JVM的核心功能,跨平台特性,Java内存区域,对象在堆中的内存分配,垃圾回收等。
编译器解释器
编译器和解释器都是将高级语言代码转换成机器码的工具,但它们之间有一些关键区别:
- 编译器:一次性将整个程序代码转换成目标机器的可执行文件,执行时无需再进行翻译,因此执行速度通常较快。但编译过程需要额外的时间,且生成的可执行文件在不同平台上不可移植。
- 解释器:逐行解释源代码,并将其转换成机器码执行。解释器不需要生成可执行文件,因此节省了编译时间,但执行速度通常较慢。另外,解释器可以实现跨平台的代码执行,因为源代码在不同平台上均需要解释器来执行。
JVM核心功能
JVM的主要作用是执行Java程序的字节码。在Java应用程序开发中,Java源代码首先被编译成字节码文件(.class文件),而不是本地机器码。
这个字节码是一种与平台无关的中间表示,可以在任何支持Java的平台上运行。
JVM字节码的执行过程大概可以分为以下几个步骤:
- 装载:虚拟机启动后,通过类加载器将.class文件加载到内存中,并进行解析。
- 链接:将被引用的类、方法、变量等符号引用转化为直接引用,并将常量池中的符号引用替换为直接引用。
- 初始化:对类进行初始化。包括执行类构造器<clinit>()方法,静态变量赋值等。
- 解释执行:将解析后的字节码逐行解释执行,根据操作码执行相应的操作。
- 编译执行:如果某个方法被多次执行,JIT编译器会将其编译为本地代码,以提高执行效率。
- 垃圾回收:JVM自动进行垃圾回收,将不再使用的对象进行回收,释放内存空间。
总的来说,JVM字节码的执行过程包括“装载-链接-初始化-解释执行/编译执行-垃圾回收”等几个步骤,其中解释执行和编译执行是主要的执行方式。
跨平台特性
JVM跨平台兼容性的原因是因为Java程序编译后生成的是字节码(ByteCode)而不是特定平台上的机器码(Machine Code)。也就是说,Java程序并不是直接翻译成本地平台上的机器码,而是转换成JVM可以识别的字节码,最终由JVM解释执行或编译成本地平台上的机器码。
也就是说JVM充当了一个中间层,负责将字节码翻译成特定操作系统的机器码。
这样做的好处是,由于Java程序并不会直接依赖于本地操作系统或硬件,所以只要有支持Java虚拟机的平台,就可以在该平台上运行Java程序,而不需要对程序进行修改。
这种跨平台机制使得Java程序可以在多个操作系统上进行编译和执行,从而使得Java成为一种性能良好、易于移植的语言。因此,JVM被认为是一种跨平台运行的虚拟机,Java也因此而被大量使用。
Java内存区域
每一个java进程都是运行在一个独立的jvm虚拟机里面的,彼此之间数据隔离不互通。
一个进程所处的Java虚拟机的内存可以用下面这张热门图片概括:
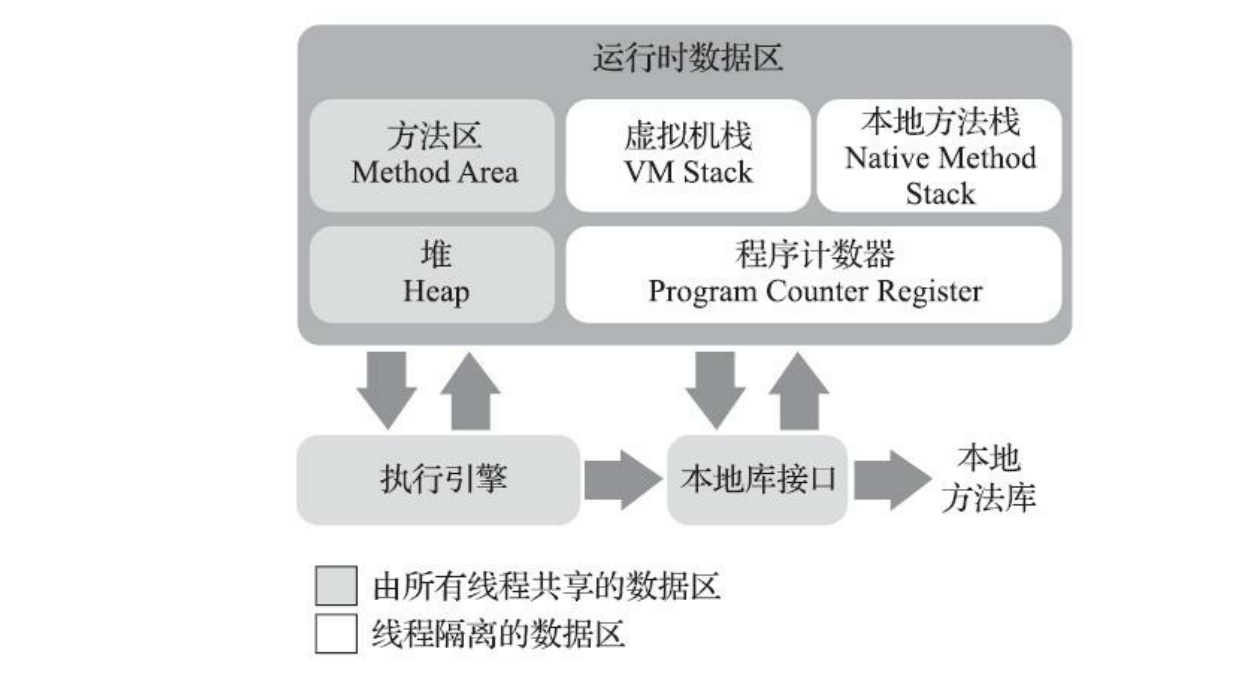
- 程序计数器:一小块区域, 线程私有 。记录了每个线程的代码执行到了哪一行,各种循环,判断都是通过这个区域存的数值来走的。Java多线程是时间分片,各个线程在一段时间内占用这个核来执行任务,这个线程切换到另一个线程,其恢复的依据也是计数器的值。
- 虚拟机栈:周期与线程相同,也是 线程私有 。每个方法执行时,都会创建一个栈帧, 栈帧里面存储方法内的局部变量表,方法出口等等信息 。每个方法执行到退出的过程,就是一个个的方法栈帧入栈出栈的过程。这个区域有两个异常,如果线程请求的栈深度大于虚拟机所允许的深度,将抛出
StackOverflowError异常;如果JVM允许动态扩展,当栈扩展时无法申请到足够的内存会抛出OutOfMemoryError异常。 - 本地方法栈:和虚拟机栈作用一样,但是服务于 本地的Native方法 。同样会抛出上面的两种异常。
- Java堆:最大的一块,所有 线程共享 的数据。几乎所有的对象实例都在这里保存。Java堆是垃圾收集器管理的内存区域。Java堆可以处于物理上不连续的内存空间中,可以选择固定大小或可扩展。如果在Java堆中没有内存完成实例分配,并且堆也无法再扩展时,Java虚拟机将会抛出
OutOfMemoryError异常。 - 方法区: 线程共享 。用于存储已被虚拟机加载的 对象类型信息、常量、静态变量、即时编译器编译后的代码缓存 等数据。对其要求比较宽松,几乎不用考虑垃圾回收,但是回收也是有必要的,主要针对常量的回收和类型卸载。如果方法区无法满足新的内存分配需求时,将抛出
OutOfMemoryError异常。- 运行时常量池,其是方法区的一部分。Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池表(Constant Pool Table),用于存放编译期生成的各种字面量与符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中。运行期间也可以将新的常量放入池中。
- 直接内存:直接内存(Direct Memory)并不是虚拟机运行时数据区的一部分,也不是《Java虚拟机规范》中定义的内存区域。但是这部分内存也被频繁地使用,而且也可能导致OutOfMemoryError异常出现。在JDK 1.4中新加入了NIO(New Input/Output)类,引入了一种基于通道(Channel)与缓冲区(Buffer)的I/O方式,它可以使用Native函数库直接分配堆外内存,然后通过一个存储在Java堆里面的
DirectByteBuffer对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在Java堆和Native堆中来回复制数据。
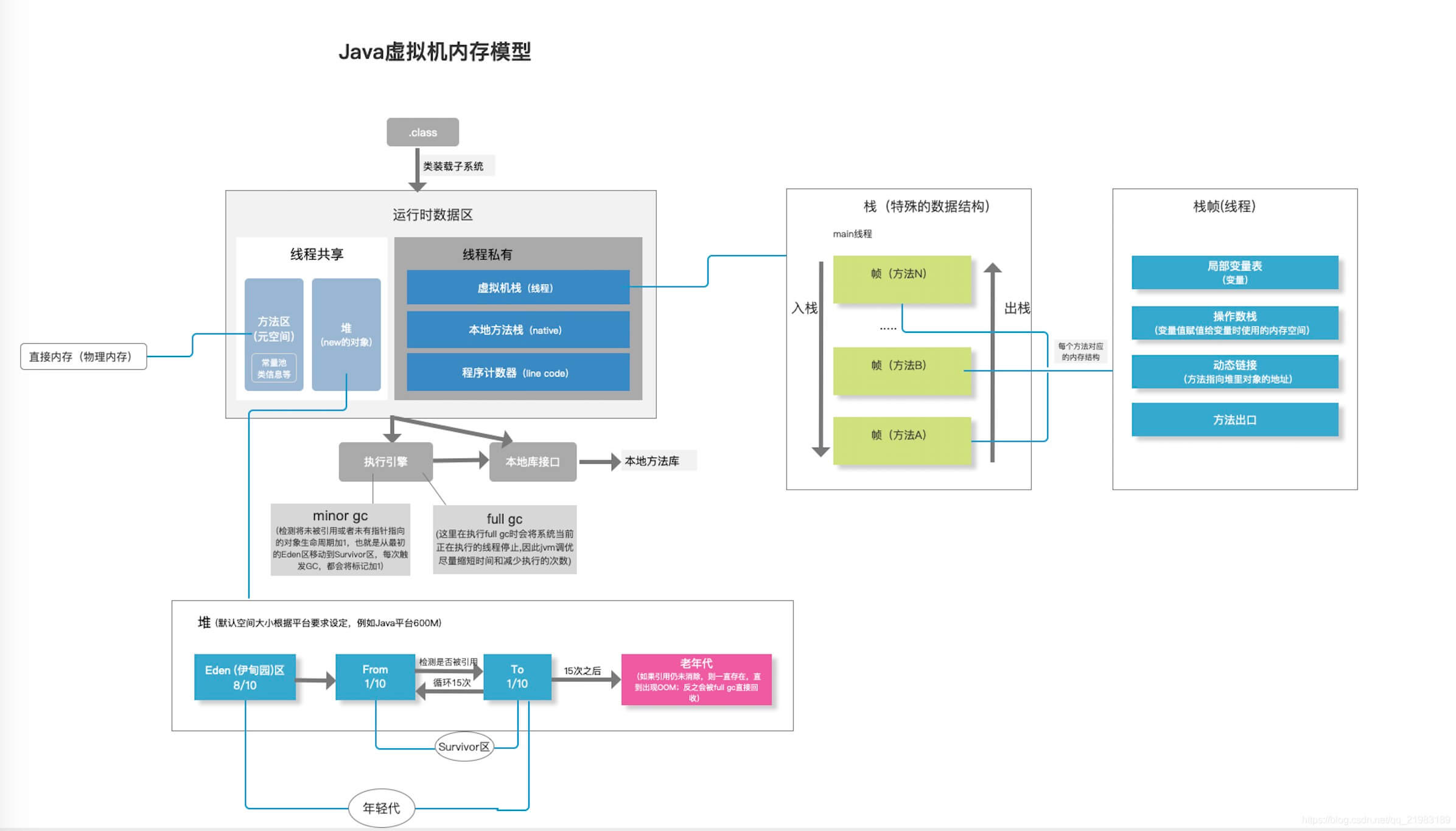
更详细的内存分配图如下:
对象创建
当遇到new字节码时,首先会检查这个指令参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载、解析和初始化过。如果没有,那必须先执行相应的类加载过程。
对象所需的内存大小在类加载完成即可完全确定下来。为对象分配内存即把一块确定大小的内存块从Java堆中分离出来使用。
假设Java堆中的内存是规整的,使用的内存在一边,空闲的内存在另一边,中间放置一个指针作为分界点指示器,那分配内存就是把指针往空闲的区域移动一段距离,这种方式叫 指针碰撞 。
如果堆内存是相互交错的,那么虚拟机就必须维护一个列表,记录哪些内存是可用的,分配内存时就是从列表中找到一块足够大的区域给对象实例,再更新纪录,这种方式叫做 空闲列表 。
采用哪种方式由垃圾收集器是否带有空间压缩整理的能力决定。
并发安全解决方案
对象创建是非常频繁的行为,可能在为对象A分配时,指针还未修改,对象B又从原来的指针指向处开始分配内存。
一种方案是采用CAS加失败重试的方式保障更新操作的原子性。
另一种方案是把内存分配的操作按照线程划分在不同空间进行,每个线程先在Java堆中划一小块作为本地线程分配缓冲,本地缓冲区用完,分配新的缓冲区才需要同步锁定。
分配收尾
分配完成后需要把分配空间全部置零,确保对象实例字段再Java代码中可以不赋初值直接使用。 接下来,Java虚拟机还要对对象进行必要的设置,例如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码(实际上对象的哈希码会延后到真正调用Object::hashCode()方法时才计算)、对象的GC分代年龄等信息。这些信息存放在对象的对象头(Object Header)之中。根据虚拟机当前运行状态的不同,如是否启用偏向锁等,对象头会有不同的设置方式。
虚拟机的视角,对象已经分配完成,从程序的视角看,对象创建才看看开始,到其构造函数。
对象在堆中的内存分配
分为三个部分:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
对象头
分为两部分,首先是对象运行时数据,如哈希码,GC分代信息,锁状态标志等,在32位和64位虚拟机上,这部分数据分别占32bit和64bit。且被设计成动态定义的数据结构,以存储尽量多的数据。 另一部分是类型指针,指向对象元数据的指针,虚拟机根据这个确定对象是哪一个类的实例,并不是所有实例都会保留类型指针。
实例数据
我们所定义的各种类型的字段类容,内存分配顺序为longs/doubles、ints、shorts/chars、bytes/booleans、oops(OrdinaryObject Pointers,OOPs)。相同宽度倾向于一起分配,先加载父类定义的,后加载子类自己的。在虚拟机的CompactFields为true时,子类里较短的变量也会插入父类的空隙中以节省空间。
对齐填充
对象的第三部分是对齐填充,这并不是必然存在的,也没有特别的含义.JVM要求对象起始地址必须是8字节的整数倍,即对象占用空间大小也必须是8字节整数倍,不够的部分就会被对齐填充。
对象的访问
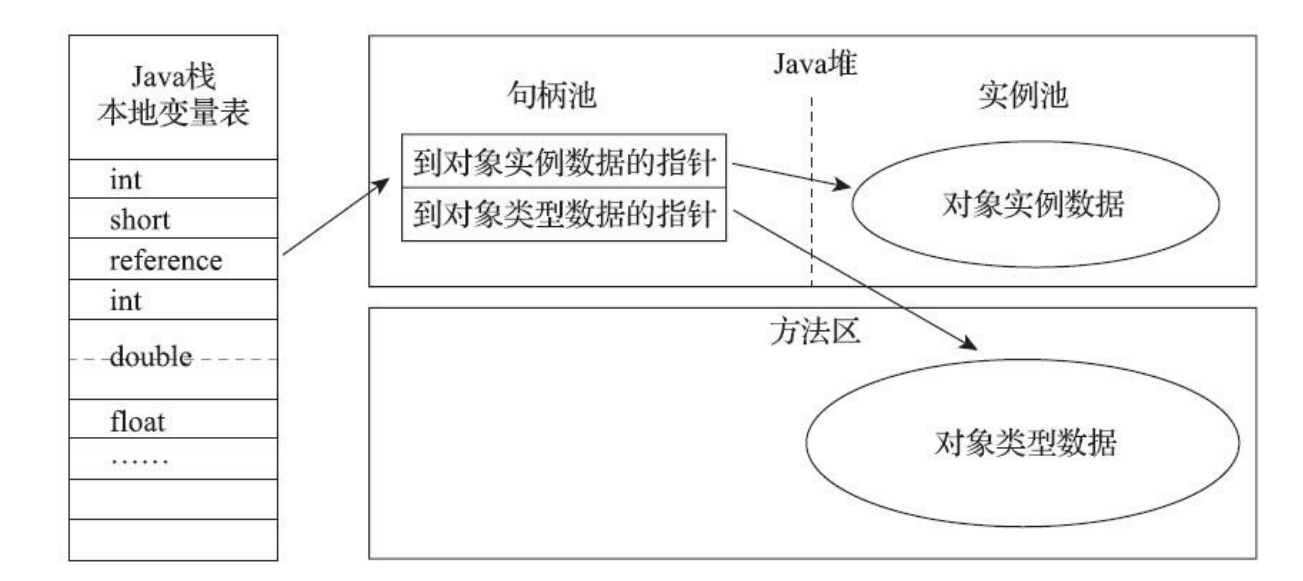
Java程序通过栈上的reference数据来操作堆上的具体对象。两种方式,通过句柄访问和指针直接访问。
句柄访问
Java堆中将可能会划分出一块内存来作为句柄池,句柄包含对象的示例数据的指针和对象类型数据的指针。
使用句柄来访问的最大好处就是reference中存储的是稳定句柄地址,在对象被移动(垃圾收集时移动对象是非常普遍的行为)时只会改变句柄中的实例数据指针,而reference本身不需要被修改。
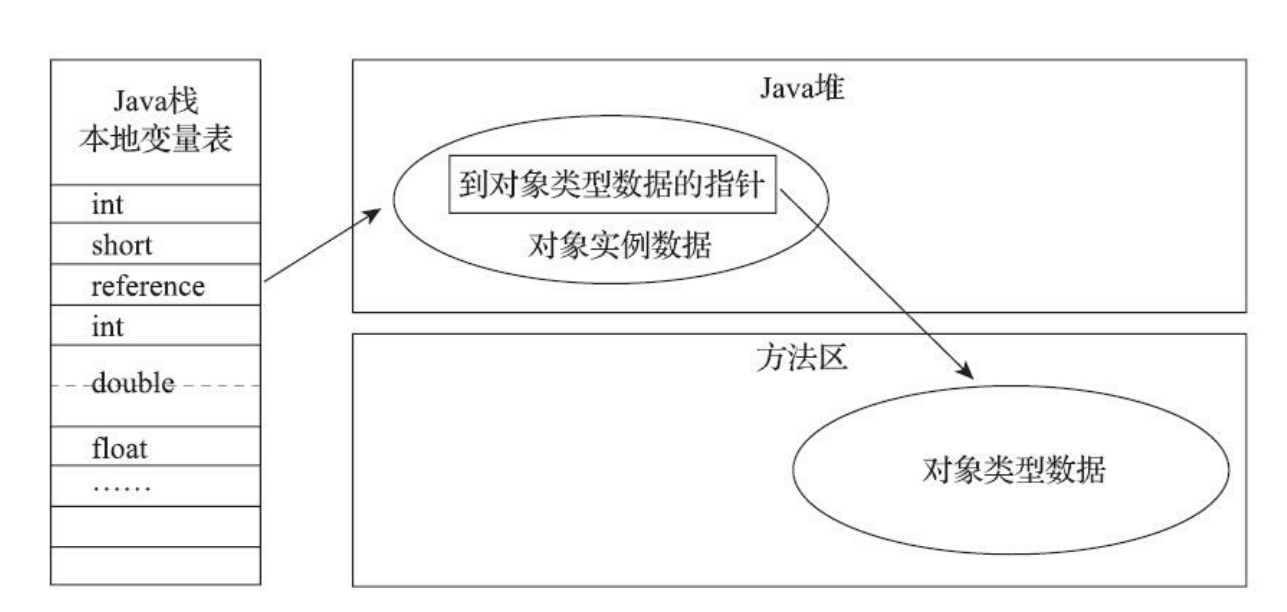
直接指针
这种方式来访问对象,Java堆中对象的内存布局就必须考虑如何放置访问类型数据的相关信息,reference中存储的直接就是对象地址,如果只是访问对象本身的话,就不需要多一次间接访问的开销。
使用直接指针来访问最大的好处就是速度更快,它节省了一次指针定位的时间开销。由于对象访问在Java中非常频繁,因此这类开销积少成多也是一项极为可观的执行成本。
垃圾回收
垃圾回收,即GC(Garbage Collection),回收无用内存空间,使其对未来实例可用的过程。由于设备的内存空间是有限的,为了防止内存空间被占满导致应用程序无法运行,就需要对无用对象占用的内存进行回收,也称垃圾回收。 垃圾回收过程中除了会清理废弃的对象外,还会清理内存碎片,完成内存整理。
判断对象是否存活的方法
GC堆内存中存放着几乎所有的对象(方法区中也存储着一部分),垃圾回收器在对该内存进行回收前,首先需要确定这些对象哪些是“活着”,哪些已经“死去”,内存回收就是要回收这些已经“死去”的对象。
那么如何其判断一个对象是否还“活着”呢?方法主要由如下两种:
引用计数法
该算法由于无法处理对象之间相互循环引用的问题,在Java中并未采用该算法,在此不做深入探究;
根搜索算法(GC ROOT Tracing)
Java中采用了该算法来判断对象是否是存活的,也叫可达性分析。
通过一系列名为 GC Roots 的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到GC Roots没有任何引用链相连(用图论来说就是从GC Roots到这个对象不可达)时,则证明对象是不可用的,即该对象是“死去”的,同理,如果有引用链相连,则证明对象可以,是“活着”的。
哪些可以作为GC Roots的对象呢?Java 语言中包含了如下几种:
1)虚拟机栈(栈帧中的本地变量表)中的引用的对象。
2)方法区中的类静态属性引用的对象。
3)方法区中的常量引用的对象。
4)本地方法栈中JNI(即一般说的Native方法)的引用的对象。
5)运行中的线程
6)由引导类加载器加载的对象
7)GC控制的对象
回收流程
现代商用虚拟机基本都采用分代收集算法来进行垃圾回收,当然这里的分代算法是一种混合算法,不同时期采用不同的算法来回收。
由于不同的对象的生命周期不一样,分代的垃圾回收策略正式基于这一点。因此,不同生命周期的对象可以采取不同的回收算法,以便提高回收效率。该算法包含三个区域:年轻代(Young Generation)、年老代(Old Generation)、持久代(Permanent Generation)。
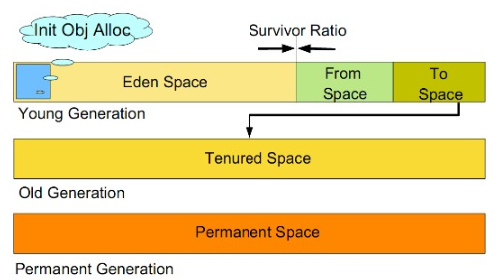
年轻代(Young Generation)
所有新生成的对象首先都是放在年轻代中。年轻代的目标就是尽可能快速地回收哪些生命周期短的对象。
新生代内存按照8:1:1的比例分为一个Eden区和两个survivor(survivor0,survivor1)区。
- Eden区,字面意思翻译过来,就是伊甸区,人类生命开始的地方。当一个实例被创建了,首先会被存储在该区域内,大部分对象在Eden区中生成。
- Survivor区,幸存者区,字面理解就是用于存储幸存下来对象。
回收时机:
- 一开始都在Eden区里,当Eden快满了就触发回收,之后,先将Eden区还存活的对象复制到一个Survivor0区,然后清空Eden区。
- 当这个Survivor0区也存放满了后,则将Eden和Survivor0区中存活对象都复制到另外一个survivor1区,然后清空Eden和这个Survivor0区,此时的Survivor0区就也是空的了。
- 然后将Survivor0区和Survivor1区交换,即保持Servivor1为空,如此往复。
这种回收算法也叫 复制算法 ,即将存活对象复制到另一个区域,然后尽可能清空原来的区域。
新生代发生的GC也叫做 Minor GC ,MinorGC发生频率比较高,不一定等Eden区满了才会触发。
为什么设置两个survivor区域?
如果只有一个eden区和一个survivor区,那么假设场景,当发生ygc后,存活对象从eden迁移到survivor,这样看好像没什么问题,很棒,但是假设eden满了,这个时候要进行ygc,那么发现此时,eden和survivor都保存有存活对象,那么你是不是要对这两个区域进行gc,找出存活对象,那么你想想是不是难度很大,还容易造成碎片,如果你使用复制算法,那么难度很大,如果你使用标记清除算法,那么容易造成内存碎片,如果你使用标记清除算法,那么耗时很长。
所以如果存在两个survivor区,那么工作就非常的 轻松,只需要在eden区和其中一个survivor(b1)找出存活对象,一次性放到另一个空的survivor(b2),然后再直接清除eden区和survivor(b1),这样效率是不是很快?快的一。
年轻代往老年代转移的条件
- 有一个JVM参数
-XX:PretenureSizeThreshold,默认值是0,表示任何情况都先把对象分配给Eden区。若设置为1048576字节,也就是1M。则表示当创建的对象大于1M时,就会直接把这个对象放入到老年区,就根本不会经过新生区了。这么做的原因:大对象在经历复制算法进行GC的时候会降低性能。 - 如果新生区中的某个对象 经历了15次GC 后,还是没有被回收掉,那么它就会被转入老年区。
- 如果当
Survivor1区不足以存放Eden区和Survivor0的存活对象时,就将存活对象 直接放到年老代 。
如果年老代也满了,就会触发一次 Major GC(Full GC) ,即新生代和年老代都进行回收。
年老代(Old Generation)
在新生代中经历了多次GC后仍然存活的对象,就会被放入到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象。
年老代比新生代内存大很多(大概比例2:1?),当年老代中存满时触发 Full GC ,其发生频率比较低,年老代对象存活时间较长,存活率比较高。
一开始对象都是任意分布的,在经历完垃圾回收之后,就会标记出哪些是存活对象,哪些是垃圾对象,然后就会把这些存活的对象在内存中进行整理移动,尽量都挪到一边去靠在一起,然后再把垃圾对象进行清除,这样做的好处就是避免了垃圾回收后产生的大片内存碎片。
即此处采用的叫 Compacting 算法,由于该区域比较大,而且通常对象生命周期比较长,compaction需要一定的时间,所以这部分的GC时间比较长,较为耗时。
所以如果系统频繁出现Full GC,会严重影响系统性能,出现卡顿。所以JVM优化的一大问题就是减少Full GC频率。
持久代(Permanent Generation)
持久代用于存放 静态文件,如Java类、方法等 ,该区域比较稳定,对GC没有显著影响。这一部分也被称为运行时常量,有的版本说JDK1.7后该部分从方法区中移到GC堆中,有的版本却说,JDK1.7后该部分被移除,有待考证。
垃圾回收时线程的表现
STW
STW事件(Stop-The-World)是指在垃圾回收过程中,Java虚拟机(JVM)需要暂停所有应用程序线程。
STW原因
垃圾回收的分析工作必须在一个能确保一致性的快照中进行。一致性指整个分析期间整个执行系统看起来像被冻结在某个时间点上,如果出现分析过程中对象引用关系还在不断变化,则分析结果的准确性无法保证。STW停顿的位置:SafePoint
安全点
安全点是指在程序执行过程中,一些特定的位置,如 方法调用、循环跳转等,这些位置被称为安全点 。在垃圾回收过程中,需要确保在这些安全点上,所有线程都已经停止执行,以确保一致性。
减少STW带来的影响
需要对垃圾收集器的配置进行优化,例如选择不同类型的垃圾收集器、调整堆大小或其他垃圾收集器参数。
例如,选择并发回收器作为垃圾回收器,如CMS、G1等,因为并发回收器主要关注的是减少STW的时长。它允许垃圾收集线程在应用程序线程运行的同时执行部分垃圾收集工作,从而减少了STW的时间。在并发回收期间,只会在特定的收集阶段发生短暂的STW。
此外,还可以通过调整堆大小和其他垃圾收集器参数来减少STW的时间。例如,可以通过调整堆大小来减少垃圾收集器在收集过程中的工作量。较小的堆大小可以减少垃圾收集器的工作量,从而减少STW的时间。
类文件的结构
魔数
每个Class文件的头4个字节称为魔数(Magic Number),它的唯一作用是确定这个文件是否为一个能被虚拟机接受的Class文件。
版本号
紧接着魔数的4个字节存储的是Class文件的版本号,Class文件的版本号每个字节都有意义,前2个字节是次版本号(Minor Version),后2个字节是主版本号(Major Version)。
常量池
紧接着主次版本号之后的是常量池入口,常量池可以理解为Class文件之中的资源仓库,它是Class文件结构中与其他项目关联最多的数据类型,也是占用Class文件空间最大的数据项目之一,同时它还是在Class文件中第一个出现的表类型数据项目。
常量池中主要存放两大类常量:字面量(Literal)和符号引用(Symbolic References)。字面量比较接近Java语言层次的常量概念,如文本字符串、被声明为final的常量值等。而符号引用则属于编译原理方面的概念,包括下面三类常量: * 被模块导出或者开放的包(Package) * 类和接口的全限定名(Fully Qualified Name) * 字段的名称和描述符(Descriptor) * 方法的名称和描述符 * 方法句柄和方法类型(Method Handle、Method Type、Invoke Dynamic) * 动态调用点和动态常量(Dynamically-Computed Call Site、Dynamically-Computed Constant)
访问标志
紧接着常量池结束的是访问标志,这个标志用于识别一些类或者接口层次的访问信息,包括:这个Class是类还是接口;是否定义为public类型;是否定义为abstract类型;如果是类的话,是否被声明为final等。
类索引、父类索引与接口索引集合
类索引(this_class)和父类索引(super_class)都是一个u2类型的数据,而接口索引集合(interfaces)是一组u2类型的数据的集合。Class文件中由这三项数据来确定这个类的继承关系。
类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名。由于Java语言的单继承性,所以父类索引只有一个,除了java.lang.Object之外,所有的Java类都有父类,因此除了java.lang.Object外,所有Java类的父类索引都不会是0。
接口索引集合就用来描述这个类实现了哪些接口,这些被实现的接口将按implements语句(如果这个类本身是一个接口,则应当是extends语句)后的接口顺序从左到右排列在接口索引集合中。
字段表集合
字段表(Field Table)用于描述接口或者类中声明的变量。字段包括类级变量以及实例级变量,但不包括在方法内部声明的局部变量。
字段表集合中不会列出从父类或者父接口中继承而来的字段,但有可能列出原本Java代码之中不存在的字段,譬如在内部类中为了保持对外部类的访问性,会自动添加指向外部类实例的字段。
方法表集合
方法表(Method Table)用于描述接口或者类中声明的方法。
方法表集合中不会列出从父类或者父接口中继承而来的方法,但有可能列出原本Java代码之中不存在的方法,譬如在内部类中为了保持对外部类的访问性,会自动添加指向外部类实例的字段。
属性表集合
属性表(Attribute Table)用于描述某些场景专有的信息。
类加载
类生命周期
一个类型从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期将会经历加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)七个阶段,其中验证、准备、解析三个部分统称为连接(Linking)。
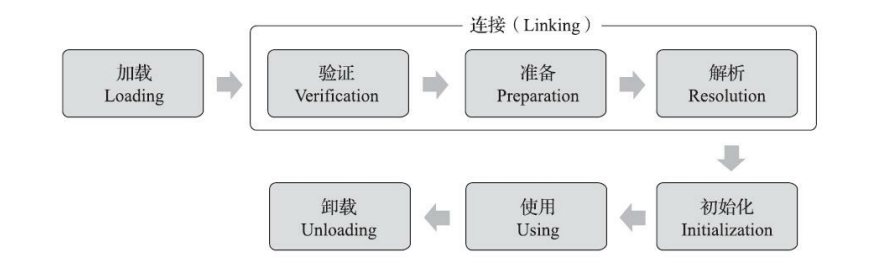
解析阶段在某些情况下可以在初始化阶段之后再开始,这是为了支持Java语言的运行时绑定特性(也称为动态绑定或晚期绑定)。
这些阶段通常都是互相交叉地混合进行的,会在一个阶段执行的过程中调用、激活另一个阶段。
类初始化的六种时机
类加载的时机看作和类初始化的时机是一致的 ,因为初始化的时候,加载,验证准备等阶段一定是在这之前完成的。
关于初始化的时机,《Java虚拟机规范》则是严格规定了 有且只有 六种情况必须立即对类进行“初始化”:
- 遇到new、getstatic、putstatic或invokestatic这四条字节码指令时,如果类型没有进行过初始化,则需要先触发其初始化阶段。能够生成这四条指令的典型Java代码场景有:
- 使用new关键字实例化对象的时候。
- 读取或设置一个类型的静态字段(被final修饰、已在编译期把结果放入常量池的静态字段除外)的时候。
- 调用一个类型的静态方法的时候。
- 使用java.lang.reflect包的方法对类型进行反射调用的时候,如果类型没有进行过初始化,则需要先触发其初始化。
- 当初始化类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化。1. 当虚拟机启动时,用户需要指定一个要执行的主类(包含main()方法的那个类),虚拟机会先初始化这个主类。
- 当使用JDK 7新加入的动态语言支持时,如果一个java.lang.invoke.MethodHandle实例最后的解析结果为REF_getStatic、REF_putStatic、REF_invokeStatic、REF_newInvokeSpecial四种类型的方法句柄,并且这个方法句柄对应的类没有进行过初始化,则需要先触发其初始化。
- 当一个接口中定义了JDK 8新加入的默认方法(被default关键字修饰的接口方法)时,如果有这个接口的实现类发生了初始化,那该接口要在其之前被初始化。
这六种场景中的行为称为对一个类型进行 主动引用 。除此之外,所有引用类型的方式都不会触发初始化,称为 被动引用 。
容易弄错的情况:
类里面的static常量
static常量在编译时,通过常量传播优化,会被放入调用该类的常量池中。外面的代码运行时如果只是调用到这个变量,本质上并没有直接引用到定义常量的类,因此不会触发定义常量的类的初始化。
class ConstClass {
static {
System.out.println("ConstClass static block");
}
public static final String HELLOWORLD = "hello world";
}
public class Test {
static {
System.out.println("Test static block");
}
public static void main(String[] args) {
System.out.println(ConstClass.HELLOWORLD);
}
}
创建一个包装类型的数组
public class SuperClass {
static {
System.out.println("SuperClass init!");
}
public static int value = 123;
}
/**
* 被动使用类字段演示二:
* 通过数组定义来引用类,不会触发此类的初始化
**/
public class NotInitialization {
public static void main(String[] args) {
SuperClass[] sca = new SuperClass[10];
}
}
没有看到“SuperClass init!”,说明没有触发类org.fenixsoft.classloading.SuperClass的初始化阶段。但是这段代码里面触发了 另一个名为“[Lorg.fenixsoft.classloading.SuperClass”的类的初始化阶段,对于用户代码来说,这并不是一个合法的类型名称,它是一个由虚拟机自动生成的、直接继承于java.lang.Object的子类,创建动作由字节码指令newarray触发。
Java语言中对数组的访问要比C/C++相对安全,很大程度上就是因为这个类包装了数组元素的访问,而C/C++中则是直接翻译为对数组指针的移动。在Java语言里,当检查到发生数组越界时会抛出 java.lang.ArrayIndexOutOfBoundsException 异常,避免了直接造成非法内存访问。
加载(Loading)过程
在加载阶段,Java虚拟机需要完成以下三件事情:
1)通过一个类的全限定名来获取定义此类的二进制字节流。 2)将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。 3)在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
对于数组类而言,情况就有所不同,数组类本身不通过类加载器创建,它是由Java虚拟机直接在内存中动态构造出来的。
通过一个类的全限定名来获取定义此类的二进制字节流”这条规则,它并没有指明二进制字节流必须得从某个Class文件中获取,确切地说是根本没有指明要从哪里获取、如何获取。
开放定义带来的好处
这也是JVM可以让其他技术借由它遍地开花的主要原因。
- 从ZIP压缩包中读取,这很常见,最终成为日后JAR、EAR、WAR格式的基础。
- 从网络中获取,这种场景最典型的应用就是Web Applet。
- 运行时计算生成,这种场景使用得最多的就是动态代理技术,在java.lang.reflect.Proxy中,就是用了ProxyGenerator.generateProxyClass()来为特定接口生成形式为“*$Proxy”的代理类的二进制字节流。
- 由其他文件生成,典型场景是JSP应用,由JSP文件生成对应的Class文件。
- 从数据库中读取,这种场景相对少见些,例如有些中间件服务器(如SAP Netweaver)可以选择把程序安装到数据库中来完成程序代码在集群间的分发。
- 可以从加密文件中获取,这是典型的防Class文件被反编译的保护措施,通过加载时解密Class文件来保障程序运行逻辑不被窥探。
验证(Verification)过程
验证阶段是非常重要的,这个阶段是否严谨,直接决定了Java虚拟机是否能承受恶意代码的攻击,从代码量和耗费的执行性能的角度上讲,验证阶段的工作量在虚拟机的类加载过程中占了相当大的比重。
文件格式验证
- 是否以魔数0xCAFEBABE开头。
- 主、次版本号是否在当前Java虚拟机接受范围之内。
- 常量池的常量中是否有不被支持的常量类型(检查常量tag标志)。
- 指向常量的各种索引值中是否有指向不存在的常量或不符合类型的常量。
- CONSTANT_Utf8_info型的常量中是否有不符合UTF-8编码的数据。
- Class文件中各个部分及文件本身是否有被删除的或附加的其他信息。
- ……
元数据验证
- 这个类是否有父类(除了java.lang.Object之外,所有的类都应当有父类)。
- 这个类的父类是否继承了不允许被继承的类(被final修饰的类)。
- 如果这个类不是抽象类,是否实现了其父类或接口之中要求实现的所有方法。
- 类中的字段、方法是否与父类产生矛盾(例如覆盖了父类的final字段,或者出现不符合规则的方法重载,例如方法参数都一致,但返回值类型却不同等)。
- ……
字节码验证
- 保证任意时刻操作数栈的数据类型与指令代码序列都能配合工作,例如不会出现类似这样的情况:在操作栈放置了一个int类型的数据,使用时却按long类型来加载入本地变量表中。
- 保证跳转指令不会跳转到方法体以外的字节码指令上。
- 保证方法体内的类型转换是有效的,例如可以把一个子类对象赋值给父类数据类型,这是安全的,但是把父类对象赋值给子类数据类型,甚至把对象赋值给与它毫无继承关系、完全不相干的一个数据类型,则是危险和不合法的。
符号引用验证
- 符号引用中通过字符串描述的全限定名是否能找到对应的类。
- 在指定类中是否存在符合方法的字段描述符及简单名称所描述的方法和字段。
- 符号引用中的类、字段、方法的访问性(private、protected、public、)是否可被当前类访问。
准备(Preparation)过程
准备阶段是正式为类中定义的变量(即静态变量,被static修饰的变量)分配内存并 设置类变量初始值 的阶段,从概念上讲,这些变量所使用的内存都应当在方法区中进行分配,但必须注意到方法区本身是一个逻辑上的区域,在JDK 7及之前, HotSpot使用永久代来实现方法区 时,实现是完全符合这种逻辑概念的;而在JDK 8及之后, 类变量则会随着Class对象一起存放在Java堆中 ,这时候“类变量在方法区”就完全是一种对逻辑概念的表述了。
需要注意,这时候进行内存分配的仅包括类变量,而不包括实例变量,实例变量将会在对象实例化时随着对象一起分配在Java堆中。
关于初始值,举一个例子:
public static int value = 123;
那变量value在准备阶段过后的初始值为0而不是123,因为这时尚未开始执行任何Java方法,而把value赋值为123的putstatic指令是程序被编译后,存放于类构造器<clinit>()方法之中,所以把value赋值为123的动作要到类的初始化阶段才会被执行。
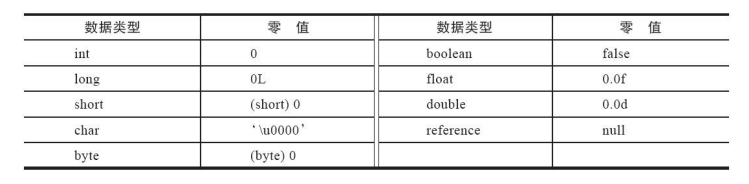
常见的类型的零值:
解析(Resolution)过程
解析阶段是Java虚拟机将常量池内的 符号引用替换为直接引用 的过程。
- 符号引用:符号引用以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可。符号引用与虚拟机实现的内存布局无关,引用的目标并不一定已经加载到内存中。
- 直接引用:直接引用可以是直接指向目标的指针、相对偏移量或是一个能间接定位到目标的句柄。直接引用是与虚拟机实现的内存布局相关的,同一个符号引用在不同虚拟机实例上翻译出来的直接引用一般不会相同。如果有了直接引用,那引用的目标必定已经在内存中存在。
《Java虚拟机规范》之中并未规定解析阶段发生的具体时间,虚拟机实现可以根据需要来自行判断,到底是在类被加载器加载时就对常量池中的符号引用进行解析,还是等到一个符号引用将要被使用前才去解析它。
解析动作主要针对 类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用点限定符 这7类符号引用进行,分别对应于常量池的CONSTANT_Class_info、CON-STANT_Fieldref_info、 CONSTANT_Methodref_info、CONSTANT_InterfaceMethodref_info、 CONSTANT_MethodType_info、CONSTANT_MethodHandle_info、CONSTANT_Dyna-mic_info和 CONSTANT_InvokeDynamic_info 8种常量类型。
类或接口的解析
如果类 D 要在解析过程中,对一个未解析过符号引用 N 的类或接口 C 进行解析,需要包括以下三个步骤:
- 如果C不是一个数组类型,那虚拟机将会把代表N的全限定名传递给D的类加载器去加载这个类C。在加载过程中,由于元数据验证、字节码验证的需要,又可能触发其他相关类的加载动作,例如加载这个类的父类或实现的接口。一旦这个加载过程出现了任何异常,解析过程就将宣告失败。
- 如果C是一个数组类型,并且数组的元素类型为对象,也就是N的描述符会是类似“[Ljava/lang/Integer”的形式,那将会按照第1点的规则加载数组元素类型。如果N的描述符如前面所假设的形式,需要加载的元素类型就是“java.lang.Integer”,接着由虚拟机生成一个代表此数组维度和元素的数组对象。
- 如果上面的步骤没有出现任何异常,那么C在虚拟机中实际上已经成为一个有效的类或接口了,但在解析完成之前还要进行符号引用验证,以确保解析结果能在虚拟机中使用。如果验证不通过,将抛出一个java.lang.IncompatibleClassChangeError异常的子类,如java.lang.IllegalAccessError、java.lang.AbstractMethodError、java.lang.InstantiationError等。
访问权限验证
如果我们说一个D拥有C的访问权限,那就意味着以下3条规则中至少有其中一条成立:
- 被访问类C是public的,并且与访问类D处于同一个模块。
- 被访问类C是public的,不与访问类D处于同一个模块,但是被访问类C的模块允许被访问类D的模块进行访问。
- 被访问类C不是public的,但是它与访问类D处于同一个包中。
字段解析
要解析一个未被解析过的字段符号引用,首先将会对字段表内class_index 项中索引的CONSTANT_Class_info符号引用进行解析,也就是字段所属的类或接口的符号引用。
如果在解析这个类或接口符号引用的过程中出现了任何异常,都会导致字段符号引用解析的失败。
如果解析成功完成,那把这个字段所属的类或接口用C表示,《Java虚拟机规范》要求按照如下步骤对C进行后续字段的搜索:
1)如果C本身就包含了简单名称和字段描述符都与目标相匹配的字段,则返回这个字段的直接引用,查找结束。 2)否则,如果在C中实现了接口,将会按照继承关系从下往上递归搜索各个接口和它的父接口,如果接口中包含了简单名称和字段描述符都与目标相匹配的字段,则返回这个字段的直接引用,查找结束。 3)否则,如果C不是java.lang.Object的话,将会按照继承关系从下往上递归搜索其父类,如果在父类中包含了简单名称和字段描述符都与目标相匹配的字段,则返回这个字段的直接引用,查找结束。 4)否则,查找失败,抛出java.lang.NoSuchFieldError异常。如果查找过程成功返回了引用,将会对这个字段进行权限验证,如果发现不具备对字段的访问权限,将抛出java.lang.IllegalAccessError异常。
方法解析
也是需要先解析出方法表的class_index项中索引的方法所属的类或接口的符号引用,如果解析成功,那么我们依然用C表示这个类,接下来虚拟机将会按照如下步骤进行后续的方法搜索:
1)由于Class文件格式中类的方法和接口的方法符号引用的常量类型定义是分开的,如果在类的方法表中发现class_index中索引的C是个接口的话,那就直接抛出java.lang.IncompatibleClassChangeError异常。 2)如果通过了第一步,在类C中查找是否有简单名称和描述符都与目标相匹配的方法,如果有则返回这个方法的直接引用,查找结束。 3)否则,在类C的父类中递归查找是否有简单名称和描述符都与目标相匹配的方法,如果有则返回这个方法的直接引用,查找结束。 4)否则,在类C实现的接口列表及它们的父接口之中递归查找是否有简单名称和描述符都与目标相匹配的方法,如果存在匹配的方法,说明类C是一个抽象类,这时候查找结束,抛出java.lang.AbstractMethodError异常。 5)否则,宣告方法查找失败,抛出java.lang.NoSuchMethodError。 最后,如果查找过程成功返回了直接引用,将会对这个方法进行权限验证,如果发现不具备对此方法的访问权限,将抛出java.lang.IllegalAccessError异常。
接口方法解析
接口方法也是需要先解析出接口方法表的class_index项中索引的方法所属的类或接口的符号引用,如果解析成功,依然用C表示这个接口,接下来虚拟机将会按照如下步骤进行后续的接口方法搜索:
1)与类的方法解析相反,如果在接口方法表中发现class_index中的索引C是个类而不是接口,那么就直接抛出java.lang.IncompatibleClassChangeError异常。 2)否则,在接口C中查找是否有简单名称和描述符都与目标相匹配的方法,如果有则返回这个方法的直接引用,查找结束。 3)否则,在接口C的父接口中递归查找,直到java.lang.Object类(接口方法的查找范围也会包括Object类中的方法)为止,看是否有简单名称和描述符都与目标相匹配的方法,如果有则返回这个方法的直接引用,查找结束。 4)对于规则3,由于Java的接口允许多重继承,如果C的不同父接口中存有多个简单名称和描述符都与目标相匹配的方法,那将会从这多个方法中返回其中一个并结束查找,《Java虚拟机规范》中并没有进一步规则约束应该返回哪一个接口方法。但与之前字段查找类似地,不同发行商实现的Javac编译器有可能会按照更严格的约束拒绝编译这种代码来避免不确定性。 5)否则,宣告方法查找失败,抛出java.lang.NoSuchMethodError异常。
初始化(Initialization)过程
进行准备阶段时,变量已经赋过一次系统要求的初始零值,而在初始化阶段,则会根据程序员通过程序编码制定的主观计划去初始化类变量和其他资源。我们也可以从另外一种更直接的形式来表达:初始化阶段就是执行类构造器<clinit>()方法的过程。
<clinit>()方法是由编译器自动收集类中的所有类变量的赋值动作和静态语句块(static{}块)中的语句 合并产生 的,编译器收集的顺序是由语句在源文件中出现的顺序决定的.
静态语句块中只能访问到定义在静态语句块之前的变量,定义在它之后的变量,在前面的静态语句块可以赋值,但是不能访问。
public class Test {
static {
i = 0; // 给变量复制可以正常编译通过
System.out.print(i); // 这句编译器会提示“非法向前引用”
}
static int i = 1;
}
Java虚拟机会保证在子类的<clinit>()方法执行前,父类的<clinit>()方法已经执行完毕。因此在Java虚拟机中第一个被执行的<clinit>()方法的类型肯定是java.lang.Object。由于父类的<clinit>()方法先执行,也就意味着父类中定义的静态语句块要优先于子类的变量赋值操作。
<clinit>()方法对于类或接口来说并不是必需的,如果一个类中没有静态语句块,也没有对变量的赋值操作,那么编译器可以不为这个类生成<clinit>()方法。
接口中不能使用静态语句块,但仍然有变量初始化的赋值操作,因此接口与类一样都会生成<clinit>()方法。但接口与类不同的是,执行接口的<clinit>()方法不需要先执行父接口的<clinit>()方法,因为只有当父接口中定义的变量被使用时,父接口才会被初始化。此外,接口的实现类在初始化时也 一样不会执行接口的<clinit>()方法。
Java虚拟机必须保证一个类的<clinit>()方法在多线程环境中被正确地加锁同步,如果多个线程同时去初始化一个类,那么只会有其中一个线程去执行这个类的<clinit>()方法, 其他线程都需要阻塞等待 ,直到活动线程执行完毕<clinit>()方法。如果在一个类的<clinit>()方法中有耗时很长的操作,那就可能造成多个线程阻塞,在实际应用中这种阻塞往往是很隐蔽的。初始化完毕之后,其他线程解除阻塞,则不会再执行<clinit>()方法,因为一个类只会被初始化一次。
类加载器
对于任意一个类,都必须由加载它的类加载器和这个类本身一起共同确立其在Java虚拟机中的唯一性,每一个类加载器,都拥有一个独立的类名称空间。
这句话可以表达得更通俗一些:比较两个类是否“相等”,只有在这两个类是由同一个类加载器加载的前提下才有意义,否则,即使这两个类来源于同一个Class文件,被同一个Java虚拟机加载,只要加载它们的类加载器不同,那这两个类就必定不相等。
举例如下:
/**
* 类加载器与instanceof关键字演示
*
* @author zzm
*/
public class ClassLoaderTest {
public static void main(String[] args) throws Exception {
ClassLoader myLoader = new ClassLoader() {
@Override
public Class<?> loadClass(String name) throws ClassNotFoundException {
try {
String fileName = name.substring(name.lastIndexOf(".") + 1)+".class";
InputStream is = getClass().getResourceAsStream(fileName);
if (is == null) {
return super.loadClass(name);
}
byte[] b = new byte[is.available()];
is.read(b);
return defineClass(name, b, 0, b.length);
} catch (IOException e) {
throw new ClassNotFoundException(name);
}
}
};
Object obj = myLoader.loadClass("org.fenixsoft.classloading.ClassLoaderTest").newInstance();
System.out.println(obj.getClass());
System.out.println(obj instanceof org.fenixsoft.classloading.ClassLoaderTest);
}
}
// 运行结果:
// class org.fenixsoft.classloading.ClassLoaderTest
// false
双亲委派模型
JVM设计了三层加载器的双亲委派模型,保证了Java程序的稳定运行。
首先问一个问题,如果所有的类都用启动类加载器有什么问题?
无法加载用户自定义类
启动类加载器的局限性:启动类加载器只负责加载JVM核心类库(如 java.lang、java.util 等位于 JAVA_HOME/lib 目录下的类),它无法加载用户自定义的类(如应用程序类)。 路径限制:启动类加载器无法加载 classpath 下的类,导致用户自定义类无法被加载和运行。
类冲突风险
如果所有类都由启动类加载器加载,不同应用或模块中的同名类会冲突,无法隔离。 无法实现模块化:现代Java应用通常需要模块化加载(如OSGi、Java 9模块系统),启动类加载器无法满足这种需求。
灵活性不足
无法动态加载类:启动类加载器无法动态加载类,而应用类加载器(如 AppClassLoader)可以根据需要动态加载类。 无法支持热部署:在Web容器或应用服务器中,热部署需要动态加载和卸载类,启动类加载器无法满足这一需求。
等等
双亲委派模型
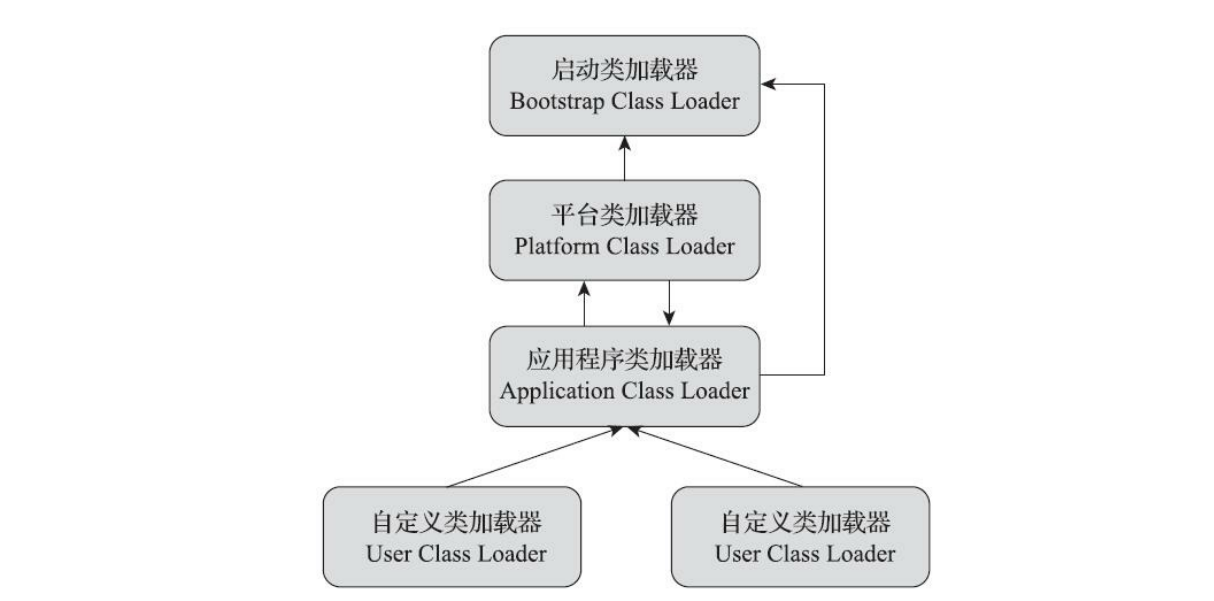
站在Java虚拟机的角度来看,只存在两种不同的类加载器:一种是 启动类加载器(BootstrapClassLoader) ,这个类加载器使用C++语言实现,是虚拟机自身的一部分;另外一种就是 其他所有的类加载器 ,这些类加载器都由Java语言实现,独立存在于虚拟机外部,并且全都继承自抽象类 java.lang.ClassLoader 。
系统提供的三个类加载器:
启动类加载器(Bootstrap Class Loader)
前面已经介绍过,这个类加载器负责加载存放在
<JAVA_HOME>\lib目录,或者被-Xbootclasspath参数所指定的路径中存放的,而且是Java虚拟机能够识别的(按照文件名识别,如rt.jar、tools.jar,名字不符合的类库即使放在lib目录中也不会被加载)类库加载到虚拟机的内存中。启动类加载器无法被Java程序直接引用,用户在编写自定义类加载器时,如果需要把加载请求委派给引导类加载器去处理,那直接使用null代替即可。
扩展类加载器(Extension Class Loader)
这个加载器由
sun.misc.Launcher$ExtClassLoader实现,它负责加载<JAVA_HOME>\lib\ext目录中,或者被java.ext.dirs系统变量所指定的路径中所有的类库,,JDK的开发团队允许用户将具有通用性的类库放置在ext目录里以扩展Java SE的功能,后面被模块化给替代扩展功能。开发者可以直接使用扩展类加载器。
应用程序类加载器(Application Class Loader)
这个类加载器由
sun.misc.Launcher$AppClassLoader来实现。由于应用程序类加载器是ClassLoader类中的getSystemClassLoader()方法的返回,所以有些场合中也称它为“系统类加载器”。它负责加载用户类路径(ClassPath)上所有的类库,开发者同样可以直接在代码中使用这个类加载器。
图解关系:
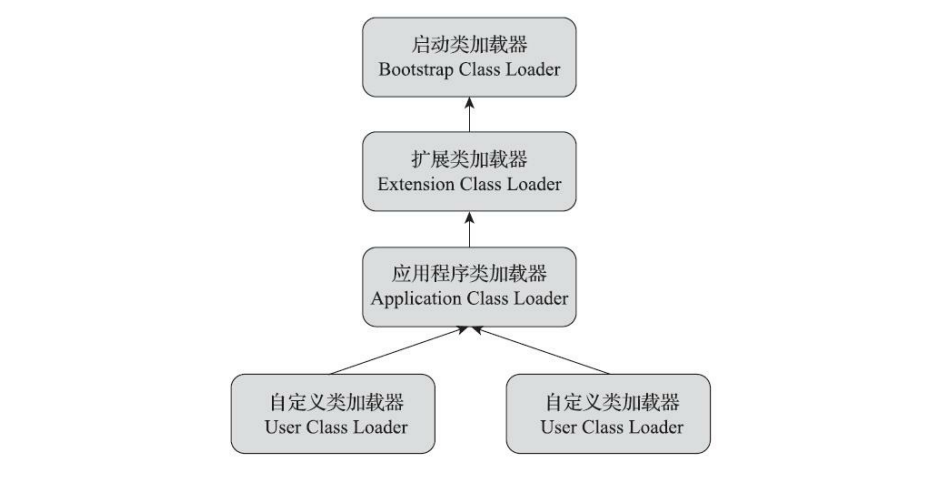
双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都应有自己的父类加载器。不过这里类加载器之间的父子关系一般不是以继承Inheritance)的关系来实现的,而是通常使用组合(Composition)关系来复用父加载器的代码。
双亲委派模型的工作过程是:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求 委派给父类加载器 去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到最顶层的启动类加载器中,只有当 父加载器反馈自己无法完成这个加载请求 (它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去完成加载。
代码实现:
protected synchronized Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException
{
// 首先,检查请求的类是否已经被加载过了
Class c = findLoadedClass(name);
if (c == null) {
try {
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// 如果父类加载器抛出ClassNotFoundException
// 说明父类加载器无法完成加载请求
}
if (c == null) {
// 在父类加载器无法加载时
// 再调用本身的findClass方法来进行类加载
c = findClass(name);
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
双亲委派模型的革新
Java历史上,出现过不符合双亲委派模型的三大事件:
第一次,是在jdk1.2的这个模型出现之前,双亲委派模型还没有出现,而java.lang.ClassLoader则在Java的第一个版本中就已经存在,面对已经存在的用户自定义类加载器的代码,Java设计者们引入双亲委派模型时不得不做出一些妥协,为了兼容这些已有代码,无法再以技术手段避免loadClass()被子类覆盖的可能性,只能在JDK 1.2之后的java.lang.ClassLoader中添加一个新的protected方法findClass(),并引导用户编写的类加载逻辑时尽可能去重写这个方法,而不是在loadClass()中编写代码。避免不符合jvm的这个设计初衷
第二次, 如果有基础类型又要调用回用户的代码 ,那该怎么办呢?
一个典型的例子便是JNDI服务,其存在的目的就是对资源进行查找和集中管理,它需要调用由其他厂商实现并部署在应用程序的ClassPath下的JNDI服务提供者接口(Service Provider Interface,SPI)的代码,现在问题来了,启动类加载器是绝不可能认识、加载这些代码的。
Java的设计团队只好引入了一个不太优雅的设计:线程上下文类加载器 (Thread Context ClassLoader)。这个类加载器可以通过java.lang.Thread类的setContext-ClassLoader()方法进行设置,如果创建线程时还未设置,它将会从父线程中继承一个,如果在应用程序的全局范围内都没有设置过的话,那这个类加载器默认就是应用程序类加载器。
有了线程上下文类加载器,程序就可以做一些“舞弊”的事情了。JNDI服务使用这个线程上下文类加载器去加载所需的SPI服务代码,这是一种父类加载器去请求子类加载器完成类加载的行为,这种行为实际上是打通了双亲委派模型的层次结构来逆向使用类加载器,已经违背了双亲委派模型的一般性原则。
但也是无可奈何的事情。Java中涉及SPI的加载基本上都采用这种方式来完成,例如JNDI、JDBC、JCE、JAXB和JBI等。不过,当SPI的服务提供者多于一个的时候,代码就只能根据具体提供者的类型来硬编码判断,为了消除这种极不优雅的实现方式,在JDK 6时,JDK提供了 java.util.ServiceLoader 类,以META-INF/services中的配置信息,辅以责任链模式,这才算是给SPI的加载提供了一种相对合理的解决方案。
第三次,是由于用户对程序动态性的追求而导致的。对于个人电脑来说,重启一次其实没有什么大不了的,但对于一些生产系统来说,关机重启一次可能就要被列为生产事故,这种情况下热部署就对软件开发者,尤其是大型系统或企业级软件开发者具有很大的吸引力。
那时候最热门的是以IBM公司主导的 JSR-291(即OSGi R4.2) 提案。
OSGi实现模块化热部署的关键是它自定义的类加载器机制的实现,每一个程序模块(OSGi中称为Bundle)都有一个自己的类加载器,当需要更换一个Bundle时,就把Bundle连同类加载器一起换掉以实现代码的热替换。在OSGi环境下,类加载器不再双亲委派模型推荐的树状结构,而是进一步发展为更加复杂的网状结构,当收到类加载请求时,OSGi将按照下面的顺序进行类搜索:
1)将以java.*开头的类,委派给父类加载器加载。 2)否则,将委派列表名单内的类,委派给父类加载器加载。 3)否则,将Import列表中的类,委派给Export这个类的Bundle的类加载器加载。 4)否则,查找当前Bundle的ClassPath,使用自己的类加载器加载。 5)否则,查找类是否在自己的Fragment Bundle中,如果在,则委派给Fragment Bundle的类加载器加载。 6)否则,查找Dynamic Import列表的Bundle,委派给对应Bundle的类加载器加载。 7)否则,类查找失败。
上面的查找顺序中只有开头两点仍然符合双亲委派模型的原则,其余的类查找都是在平级的类加载器中进行的。
模块化
为了能够实现模块化的关键目标—— 可配置的封装隔离机制 ,Java虚拟机对类加载架构也做出了相应的变动调整,才使模块化系统得以顺利地运作。
除了像Jar包一样充当代码容器以外,Java的模块定义还包含以下内容:
- 依赖其他模块的列表。
- 导出的包列表,即其他模块可以使用的列表。
- 开放的包列表,即其他模块可反射访问模块的列表。
- 使用的服务列表。
- 提供服务的实现列表。
JDK 9之前,如果类路径中缺失了运行时依赖的类型,那就只能等程序运行到发生该类型的加载、链接时才会报出运行的异常。
而在JDK 9以后,如果启用了模块化进行封装,模块就可以声明对其他模块的显式依赖,这样Java虚拟机就能够在启动时验证应用程序开发阶段设定好的依赖关系在运行期是否完备,如有缺失那就直接启动失败,从而避免了很大一部分由于类型依赖而引发的运行时异常。
可配置的封装隔离机制还解决了原来类路径上跨JAR文件的public类型的可访问性问题。JDK 9中的public类型不再意味着程序的所有地方的代码都可以随意访问到它们,模块提供了更精细的可访问性控制,必须明确声明其中哪一些public的类型可以被其他哪一些模块访问,这种访问控制也主要是在类加载过程中完成的。
兼容传统类路径加载机制
JDK 9提出了与“类路径”(ClassPath)相对应的“模块路径”(ModulePath)的概念。简单来说,就是某个类库到底是模块还是传统的JAR包,只取决于它存放在哪种路径上。
JAR文件在类路径的访问规则:所有类路径下的JAR文件及其他资源文件,都被视为自动打包在一个匿名模块(Unnamed Module)里,这个匿名模块几乎是没有任何隔离的,它可以看到和使用类路径上所有的包、JDK系统模块中所有的导出包,以及模块路径上所有模块中导出的包。
模块在模块路径的访问规则:模块路径下的具名模块(Named Module)只能访问到它依赖定义中列明依赖的模块和包,匿名模块里所有的内容对具名模块来说都是不可见的,即具名模块看不见传统JAR包的内容。
JAR文件在模块路径的访问规则:如果把一个传统的、不包含模块定义的JAR文件放置到模块路径中,它就会变成一个自动模块(Automatic Module)。尽管不包含module-info.class,但自动模块将默认依赖于整个模块路径中的所有模块,因此可以访问到所有模块导出的包,自动模块也默认导出自己所有的包。
以上3条规则保证了即使Java应用依然使用传统的类路径,升级到JDK 9对应用来说几乎不会有任何感觉。
模块化升级后的类加载器结构
首先,是扩展类加载器(Extension Class Loader)被平台类加载器(Platform Class Loader)取代。这其实是一个很顺理成章的变动,既然整个JDK都基于模块化进行构建(原来的rt.jar和tools.jar被拆分成数十个JMOD文件),其中的Java类库就已天然地满足了可扩展的需求,那自然无须再保留 <JAVA_HOME>\lib\ext 目录,此前使用这个目录或者java.ext.dirs系统变量来扩展JDK功能的机制已经没有继续存在的价值了
其次,平台类加载器和应用程序类加载器都不再派生自java.net.URLClassLoader,如果有程序直接依赖了这种继承关系,或者依赖了URLClassLoader类的特定方法,那代码很可能会在JDK 9及更高版 本的JDK中崩溃。现在启动类加载器、平台类加载器、应用程序类加载器全都继承于jdk.internal.loader.BuiltinClassLoader,在BuiltinClassLoader中实现了新的模块化架构下类如何从模块中加载的逻辑,以及模块中资源可访问性的处理。
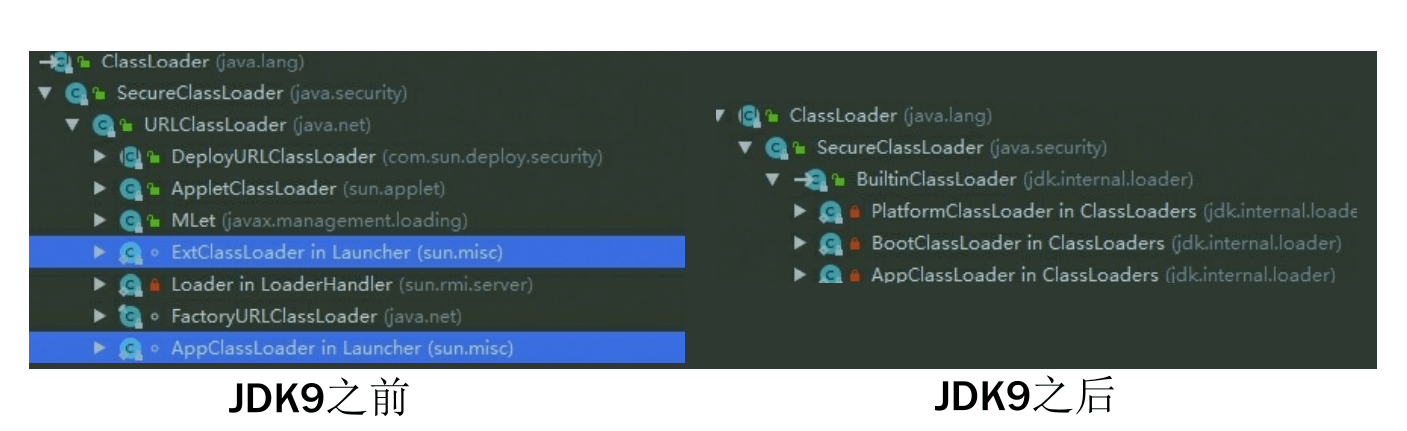
启动类加载器现在是在Java虚拟机内部和Java类库共同协作实现的类加载器,尽管有了BootClassLoader这样的Java类,但为了与之前的代码保持兼容,所有在获取启动类加载器的场景(譬如Object.class.getClassLoader())中仍然会返回null来代替,而不会得到BootClassLoader的实例。
- 启动类加载器负责:
java.base java.security.sasl
java.datatransfer java.xml
java.desktop jdk.httpserver
java.instrument jdk.internal.vm.ci
java.logging jdk.management
java.management jdk.management.agent
java.management.rmi jdk.naming.rmi
java.naming jdk.net
java.prefs jdk.sctp
java.rmi jdk.unsupported
- 平台类加载器负责加载的模块:
java.activation* jdk.accessibility
java.compiler* jdk.charsets
java.corba* jdk.crypto.cryptoki
java.scripting jdk.crypto.ec
java.se jdk.dynalink
java.se.ee jdk.incubator.httpclient
java.security.jgss jdk.internal.vm.compiler*
java.smartcardio jdk.jsobject
java.sql jdk.localedata
java.sql.rowset jdk.naming.dns
java.transaction* jdk.scripting.nashorn
java.xml.bind* jdk.security.auth
java.xml.crypto jdk.security.jgss
java.xml.ws* jdk.xml.dom
java.xml.ws.annotation* jdk.zipfs
- 应用程序类加载器负责加载的模块:
jdk.aot jdk.jdeps
jdk.attach jdk.jdi
jdk.compiler jdk.jdwp.agent
jdk.editpad jdk.jlink
jdk.hotspot.agent jdk.jshell
jdk.internal.ed jdk.jstatd
jdk.internal.jvmstat jdk.pack
jdk.internal.le jdk.policytool
jdk.internal.opt jdk.rmic
jdk.jartool jdk.scripting.nashorn.shell
jdk.javadoc jdk.xml.bind*
jdk.jcmd jdk.xml.ws*
jdk.jconsole
字节码执行
物理机的执行引擎是直接建立在处理器、缓存、指令集和操作系统层面上的,而虚拟机的执行引擎则是由软件自行实现的,因此可以不受物理条件制约地定制指令集与执行引擎的结构体系,能够执行那些不被硬件直接支持的指令集格式。
在不同的虚拟机实现中,执行引擎在执行字节码的时候,通常会有解释执行(通过解释器执行)和编译执行(通过即时编译器产生本地代码执行)两种 选择,也可能两者兼备,还可能会有同时包含几个不同级别的即时编译器一起工作的执行引擎。
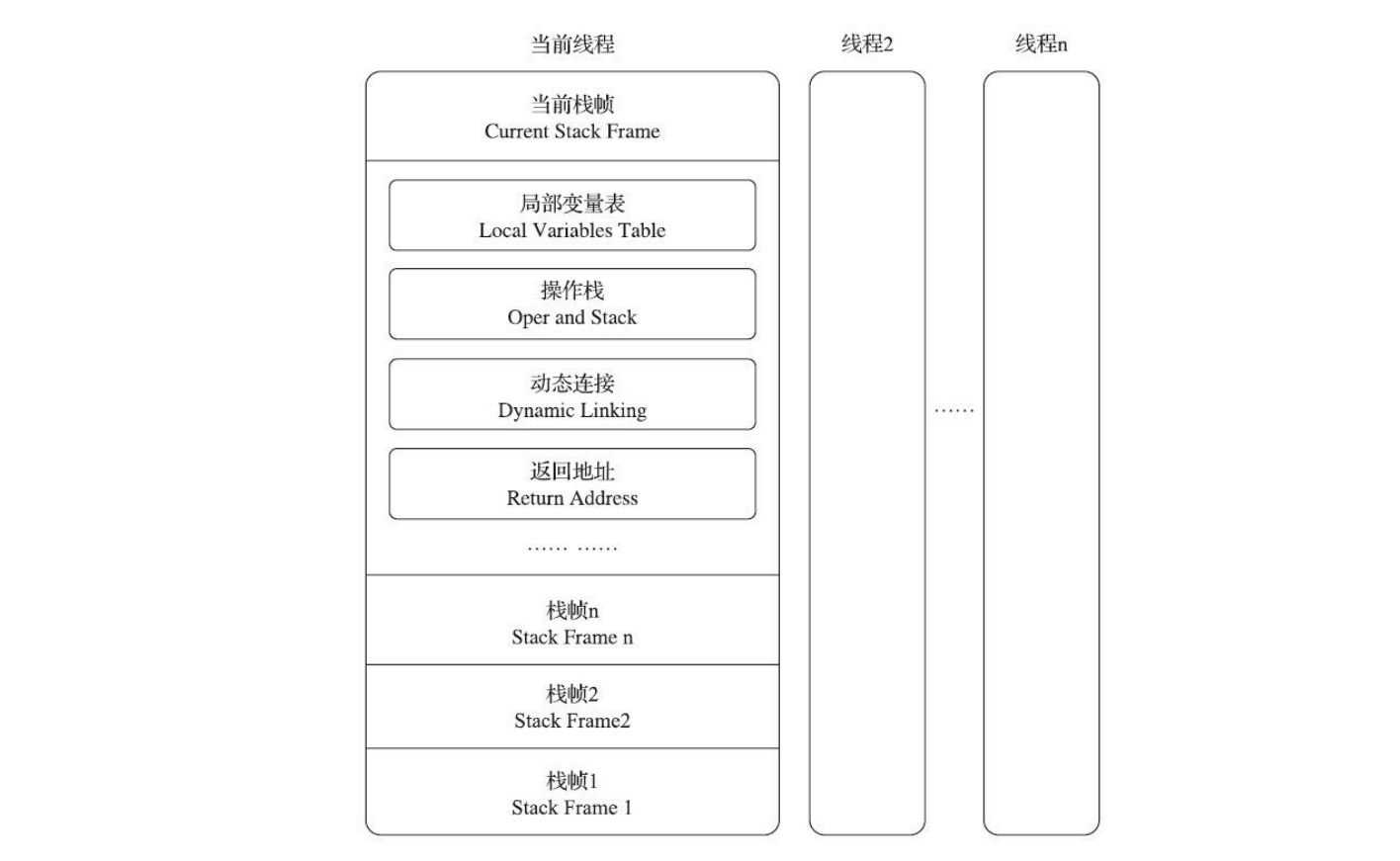
栈帧
Java虚拟机以方法作为最基本的执行单元,“栈帧”(Stack Frame)则是用于支持虚拟机进行方法调用和方法执行背后的数据结构,它也是虚拟机运行时数据区中的虚拟机栈(Virtual MachineStack)的栈元素。栈帧存储了方法的局部变量表、操作数栈、动态连接和方法返回地址等信息。
每一个方法从调用开始至执行结束的过程,都对应着一个栈帧在虚拟机栈里面从入栈到出栈的过程。每一个栈帧都包括了局部变量表、操作数栈、动态连接、方法返回地址和一些额外的附加信息。在编译Java程序源码的时候,栈帧中需要多大的局部变量表,需要多深的操作数栈就已经被分析计算出来,并且写入到方法表的Code属性之中。换言之,一个栈帧需要分配多少内存,并不会受到程序运行期变量数据的影响,而仅仅取决于程序源码和具体的虚拟机实现的栈内存布局形式。
一个线程中的方法调用链可能会很长。
- 以Java程序的角度来看,同一时刻、同一条线程里面,在调用堆栈的所有方法都同时处于执行状态。
- 而对于执行引擎来讲,在活动线程中,只有位于栈顶的方法才是在运行的,只有位于栈顶的栈帧才是生效的,其被称为“当前栈帧”(Current Stack Frame),与这个栈帧所关联的方法被称为“当前方法”(Current Method)。执行引擎所运行的所有字节码指令都只针对当前栈帧进行操作。
局部变量表
局部变量表(Local Variables Table)是一组变量值的存储空间,用于存放方法参数和方法内部定义的局部变量。在Java程序被编译为Class文件时,就在方法的Code属性的max_locals数据项中确定了该方法所需分配的局部变量表的最大容量。
局部变量表的容量以变量槽(Variable Slot)为最小单位,《Java虚拟机规范》中很有导向性地说到 每个变量槽都应该能存放一个boolean、byte、char、short、int、float、reference或returnAddress类型的数据 ,这8种数据类型,都可以使用32位或更小的物理内存来存储,这种描述允许变量槽的长度可以随着处理器、操作系统或虚拟机实现的不同而发生变化,保证了即使在64位虚拟机中使用了64位的物理内存空间去实现一个变量槽,虚拟机仍要使用对齐和补白的手段让变量槽在外观上看起来与32位虚拟机中的一致。
操作数栈
操作数栈(Operand Stack)也常被称为操作栈,同局部变量表一样,操作数栈的最大深度也在编译的时候被写入到Code属性的max_stacks数据项之中。
操作数栈的每一个元素都可以是包括long和double在内的任意Java数据类型。32位数据类型所占的栈容量为1,64位数据类型所占的栈容量为2。
Javac编译器的数据流分析工作保证了在方法执行的任何时候,操作数栈的深度都不会超过在max_stacks数据项中设定的最大值。当一个方法刚刚开始执行的时候,这个方法的操作数栈是空的,在方法的执行过程中,会有各种 字节码指令往操作数栈中写入和提取内容,也就是出栈和入栈操作。
譬如在做算术运算的时候是通过将运算涉及的操作数栈压入栈顶后调用运算指令来进行的,又譬如在调用其他方法的时候是通过操作数栈来进行方法参数的传递。举个例子,例如整数加法的字节码指令iadd,这条指令在运行的时候要求操作数栈中最接近栈顶的两个元素已经存入了两个int型的数值,当执行这个指令时,会把这两个int值出栈并相加,然后将相加的结果重新入栈。
操作数栈中元素的数据类型必须与字节码指令的序列严格匹配,在编译程序代码的时候,编译器必须要严格保证这一点,在类校验阶段的数据流分析中还要再次验证这一点。
再以上面的iadd指令为例,这个指令只能用于整型数的加法,它在执行时,最接近栈顶的两个元素的数据类型必须为int型,不能出现一个long和一个float使用iadd命令相加的情况。另外在概念模型中,两个不同栈帧作为不同方法的虚拟机栈的元素,是完全相互独立的。
但是在大多虚拟机的实现里都会进行一些优化处理,令两个栈帧出现一部分重叠。让下面栈帧的部分操作数栈与上面栈帧的部分局部变量表重叠在一起,这样做不仅节约了一些空间,更重要的是在进行方法调用时就可以直接共用一部分数据,无须进行额外的参数复制传递了。
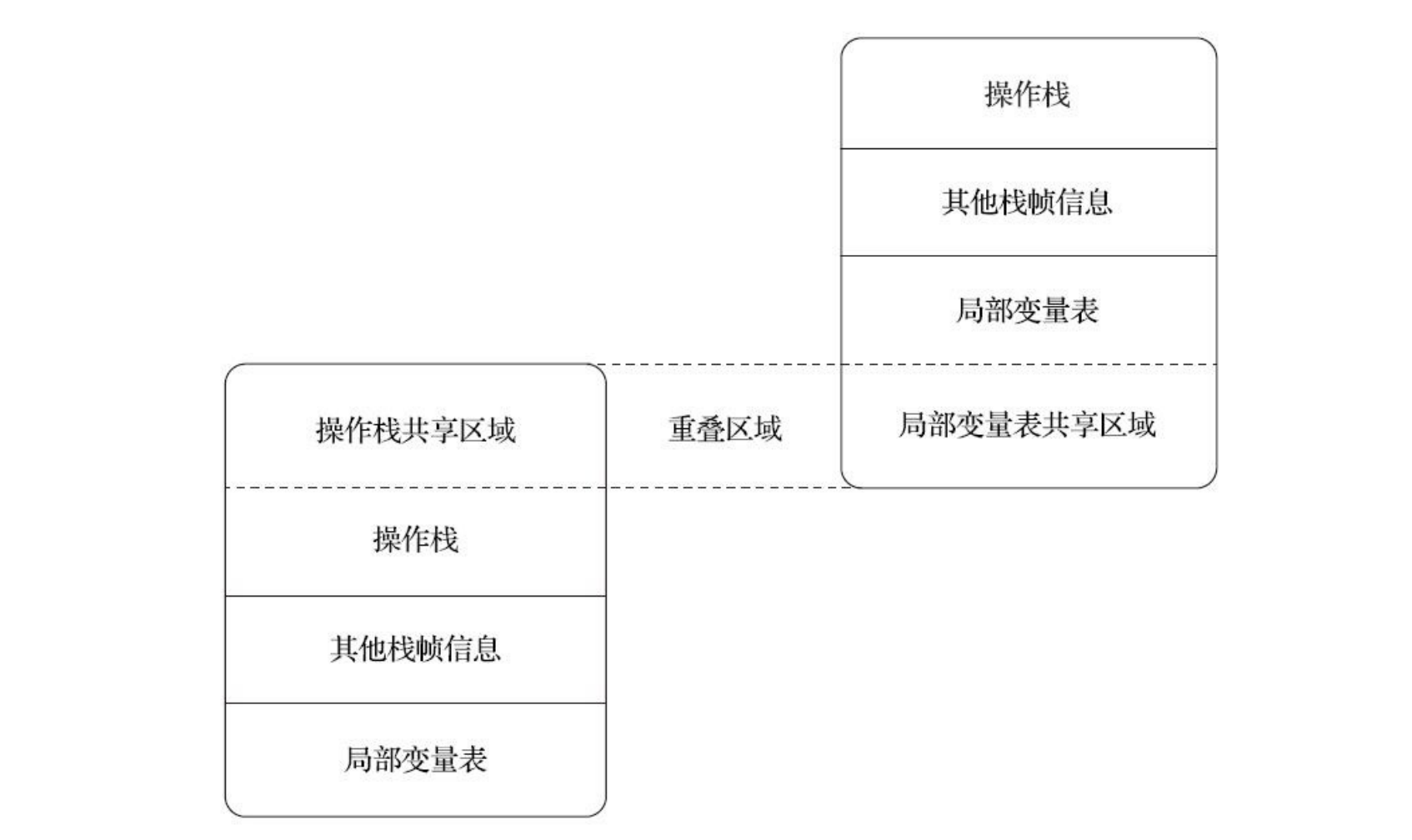
Java虚拟机的解释执行引擎被称为“基于栈的执行引擎”,里面的“栈”就是操作数栈。
动态连接
每个栈帧都包含一个指向运行时常量池中该栈帧所属方法的引用,持有这个引用是为了支持方法调用过程中的动态连接(Dynamic Linking)。
Class文件的常量池中存有大量的符号引用,字节码中的方法调用指令就以常量池里指向方法的符号引用作为参数。
- 这些符号引用一部分会在类加载阶段或者第一次使用的时候就被转化为直接引用,这种转化被称为静态解析。
- 另外一部分将在每一次运行期间都转化为直接引用,这部分就称为动态连接。
方法返回地址
当一个方法开始执行后,只有两种方式退出这个方法。
第一种方式是执行引擎遇到 任意一个方法返回的字节码指令 ,这时候可能会有返回值传递给上层的方法调用者,这种退出方法的方式称为“正常调用完成”(Normal Method Invocation Completion)。
另外一种退出方式是在 方法执行的过程中遇到了异常 ,并且这个异常没有在方法体内得到妥善处理。这种退出方法的方式称为“异常调用完成(Abrupt Method Invocation Completion)”。一个方法使用异常完成出口的方式退出,是不会给它的上层调用者提供任何返回值的。
无论采用何种退出方式,在方法退出之后,都必须 返回到最初方法被调用时的位置 ,程序才能继续执行,方法返回时可能需要在栈帧中保存一些信息,用来帮助恢复它的上层主调方法的执行状态。一般来说,方法正常退出时,主调方法的PC计数器的值就可以作为返回地址,栈帧中很可能会保存这个计数器。而方法异常退出时,返回地址是要通过异常处理器表来确定的,栈帧中就一般不会保存这部分信息。
方法退出的过程实际上等同于把当前栈帧出栈,因此退出时可能执行的操作有: 恢复上层方法的局部变量表和操作数栈,把返回值(如果有的话)压入调用者栈帧的操作数栈中,调整PC计数器的值以指向方法调用指令后面的一条指令 等。
方法调用
方法调用并不等同于方法中的代码被执行,方法调用阶段唯一的任务就是 确定被调用方法的版本 (即调用哪一个方法),暂时还未涉及方法内部的具体运行过程。在程序运行时,进行方法调用是最普遍、最频繁的操作之一。Class文件的编译过程中不包含传统程序语言编译的连接步骤, 一切方法调用在Class文件里面存储的都只是符号引用 ,而不是方法在实际运行时内存布局中的入口地址(也就是之前说的直接引用)。这个特性给Java带来了更强大的动态扩展能力,但也 使得Java方法调用过程变得相对复杂 ,某些调用需要在类加载期间,甚至到运行期间才能确定目标方法的直接引用。
解析调用
不同类型的方法,字节码指令集里设计了不同的指令。在Java虚拟机支持以下5条方法调用字节码指令,分别是:
- invokestatic。用于调用静态方法。
- invokespecial。用于调用实例构造器
<init>()方法、私有方法和父类中的方法。 - invokevirtual。用于调用所有的虚方法。
- invokeinterface。用于调用接口方法,会在运行时再确定一个实现该接口的对象。
- invokedynamic。先在运行时动态解析出调用点限定符所引用的方法,然后再执行该方法。前面4条调用指令,分派逻辑都固化在Java虚拟机内部,而invokedynamic指令的分派逻辑是由用户设定的引导方法来决定的。
只要能被 invokestatic和invokespecial 指令调用的方法,都可以在解析阶段中确定唯一的调用版本,Java语言里符合这个条件的方法共有静态方法、私有方法、实例构造器、父类方法4种,再加上被final修饰的方法(尽管它使用invokevirtual指令调用),这5种方法调用会 在类加载的时候就可以把符号引用解析为该方法的直接引用 。这些方法统称为“非虚方法”(Non-Virtual Method),与之相反,其他方法就被称为“虚方法”(Virtual Method)。
在类加载的解析阶段,会将其中的一部分符号引用转化为直接引用,这种解析能够成立的前提是:方法在程序真正运行之前就有一个可确定的调用版本,并且这个方法的调用版本在运行期是不可改变的。换句话说,调用目标在程序代码写好、编译器进行编译那一刻就已经确定下来。这类方法的调用被称为解析(Resolution)。
静态分派调用
方法静态分派演示:
/**
* 方法静态分派演示
* @author zzm
*/
public class StaticDispatch {
static abstract class Human {
}
static class Man extends Human {
}
static class Woman extends Human {
}
public void sayHello(Human guy) {
System.out.println("hello,guy!");
}
public void sayHello(Man guy) {
System.out.println("hello,gentleman!");
}
public void sayHello(Woman guy) {
System.out.println("hello,lady!");
}
public static void main(String[] args) {
Human man = new Man();
Human woman = new Woman();
StaticDispatch sr = new StaticDispatch();
sr.sayHello(man);
sr.sayHello(woman);
}
}
// hello,guy
// hello,guy
把上面代码中的“Human”称为变量的 “静态类型”(Static Type) ,或者叫“外观类型”(Apparent Type),后面的“Man”则被称为变量的 “实际类型”(Actual Type) 或者叫“运行时类型”(Runtime Type)。
静态类型和实际类型在程序中都可能会发生变化,区别是静态类型的变化仅仅在使用时发生,变量本身的静态类型不会被改变,并且 最终的静态类型是在编译期可知的;而实际类型变化的结果在运行期才可确定 ,编译器在编译程序的时候并不知道一个对象的实际类型是什么。
例如:
// 实际类型变化
Human human = (new Random()).nextBoolean() ? new Man() : new Woman();
// 静态类型变化
sr.sayHello((Man) human)
sr.sayHello((Woman) human)
代码中故意定义了两个静态类型相同,而实际类型不同的变量,但 虚拟机(或者准确地说是编译器)在重载时是通过参数的静态类型而不是实际类型作为判定依据的 。由于静态类型在编译期可知,所以在编译阶段,Javac编译器就根据参数的静态类型决定了会使用哪个重载版本,因此选择了sayHello(Human)作为调用目标,并把这个方法的符号引用写到main()方法里的两条 invokevirtual 指令的参数中。
所有依赖静态类型来决定方法执行版本的分派动作,都称为静态分派。静态分派的最典型应用表现就是方法重载。静态分派发生在编译阶段,因此确定静态分派的动作实际上不是由虚拟机来执行的。
需要注意Javac编译器虽然能确定出方法的重载版本,但在很多情况下这个重载版本并不是“唯一”的,往往只能确定一个“相对更合适的”版本。
以下举例可以看出这一点:
重载方法匹配优先级
public class Overload {
public static void sayHello(Object arg) {
System.out.println("hello Object");
}
public static void sayHello(int arg) {
System.out.println("hello int");
}
public static void sayHello(long arg) {
System.out.println("hello long");
}
public static void sayHello(Character arg) {
System.out.println("hello Character");
}
public static void sayHello(char arg) {
System.out.println("hello char");
}
public static void sayHello(char... arg) {
System.out.println("hello char ...");
}
public static void sayHello(Serializable arg) {
System.out.println("hello Serializable");
}
public static void main(String[] args) {
sayHello('a');
}
}
输出:
hello char
因为a是一个字符类型,如果注释掉sayHello(char arg)方法,那么输出的结果将是:
hello int
这里做了 一次自动类型转换 ,’a’除了可以代表一个字符串,还可以代表数字97(字符’a’的Unicode数值为十进制数字97),因此参数类型为int的重载也是合适的。继续注释掉sayHello(int arg)方法,那么输出的结果将是:
hello long
时发生了 两次自动类型转换 ,’a’转型为整数97之后,进一步转型为长整数97L,匹配了参数类型为long的重载。笔者在代码中没有写其他的类型如float、double等的重载,不过实际上自动转型还能继续发生多次,按照 char>int>long>float>double 的顺序转型进行匹配,但不会匹配到byte和short类型的重载,因为char到byte或short的转型是不安全的。
继续注释掉sayHello(long arg)方法,那么输出的结果将是:
hello Character
这里发生了 一次自动装箱 ,’a’被包装为了Character类型的对象。注释掉sayHello(Character arg)方法,那么输出的结果将是:
hello Serializable
是因为java.lang.Serializable是java.lang.Character类实现的一个接口,当自动装箱之后发现还是找不到装箱类,但是找到了装箱类所实现的接口类型,所以紧接着又发生一次自动转型。
继续注释掉sayHello(Serializable arg)方法,输出会变为:
hello Object
这时是char装箱后转型为父类了,如果有多个父类,那将在继承关系中从下往上开始搜索,越接上层的优先级越低。即使方法调用传入的参数值为null时,这个规则仍然适用。我们把sayHello(Objectarg)也注释掉,输出将会变为:
hello char …
7个重载方法已经被注释得只剩1个了,可见变长参数的重载优先级是最低的,这时候字符’a’被当作了一个char[]数组的元素。
动态分派
下Java语言里动态分派的实现过程,它与Java语言多态性的另外一个重要体现——重写(Override)有着很密切的关联。
/**
* 方法动态分派演示
* @author zzm
*/
public class DynamicDispatch {
static abstract class Human {
protected abstract void sayHello();
}
static class Man extends Human {
@Override
protected void sayHello() {
System.out.println("man say hello");
}
}
static class Woman extends Human {
@Override
protected void sayHello() {
System.out.println("woman say hello");
}
}
public static void main(String[] args) {
Human man = new Man();
Human woman = new Woman();
man.sayHello();
woman.sayHello();
man = new Woman();
man.sayHello();
}
}
// man say hello
// woman say hello
// woman say hello
显然这里选择调用的方法版本是不可能再根据静态类型来决定的,因为静态类型同样都是Human的两个变量man和woman在调用sayHello()方法时产生了不同的行为,甚至变量man在两次调用中还执行了两个不同的方法。
上面代码编译的字节码:
public static void main(java.lang.String[]);
Code:
Stack=2, Locals=3, Args_size=1
0: new #16; //class org/fenixsoft/polymorphic/DynamicDispatch$Man
3: dup
4: invokespecial #18; //Method org/fenixsoft/polymorphic/Dynamic Dispatch$Man."<init>":()V
7: astore_1
8: new #19; //class org/fenixsoft/polymorphic/DynamicDispatch$Woman
11: dup
12: invokespecial #21; //Method org/fenixsoft/polymorphic/DynamicDispatch$Woman."<init>":()V
15: astore_2
16: aload_1
17: invokevirtual #22; //Method org/fenixsoft/polymorphic/Dynamic Dispatch$Human.sayHello:()V
20: aload_2
21: invokevirtual #22; //Method org/fenixsoft/polymorphic/Dynamic Dispatch$Human.sayHello:()V
24: new #19; //class org/fenixsoft/polymorphic/DynamicDispatch$Woman
27: dup
28: invokespecial #21; //Method org/fenixsoft/polymorphic/DynamicDispatch$Woman."<init>":()V
31: astore_1
32: aload_1
33: invokevirtual #22; //Method org/fenixsoft/polymorphic/Dynamic Dispatch$Human.sayHello:()V
36: return
16和20行的aload指令分别把刚刚创建的两个对象的引用压到栈顶,这两个对象是将要执行的 sayHello()方法的所有者,称为接收者(Receiver) ;17和21行是方法调用指令,这两条调用指令单从字节码角度来看,无论是指令(都是 invokevirtual )还是参数(都是常量池中第22项的常量,注释显示了这个常量是Human.sayHello()的符号引用)都完全一样,但是这两句指令最终执行的目标方法并不相同。
invokevirtual是如何确定调用方法版本、如何实现多态的?
1)找到操作数栈顶的第一个元素 所指向的对象的实际类型 ,记作C。
2)如果在类型C中找到与常量中的描述符和简单名称都相符的方法,则进行访问权限校验,如果通过则 返回这个方法的直接引用 ,查找过程结束;不通过则返回java.lang.IllegalAccessError异常。
3)否则,按照继承关系从下往上依次对C的各个父类进行第二步的搜索和验证过程。
4)如果始终没有找到合适的方法,则抛出java.lang.AbstractMethodError异常。
正是因为invokevirtual指令执行的第一步就是在运行期确定接收者的实际类型,所以两次调用中的invokevirtual指令并不是把常量池中方法的符号引用解析到直接引用上就结束了,还会根据方法接收者的实际类型来选择方法版本,这个过程就是Java语言中方法重写的本质。我们把这种 在运行期根据实际类型确定方法执行版本的分派过程称为动态分派 。
既然这种多态性的根源在于虚方法调用指令invokevirtual的执行逻辑,那自然我们得出的结论就只会对方法有效,对字段是无效的,因为字段不使用这条指令。事实上,在Java里面只有虚方法存在,字段永远不可能是虚的,换句话说,字段永远不参与多态,哪个类的方法访问某个名字的字段时,该 名字指的就是这个类能看到的那个字段。当子类声明了与父类同名的字段时,虽然在子类的内存中两个字段都会存在,但是子类的字段会遮蔽父类的同名字段。
单分派和多分派
方法的接收者与方法的参数 统称为方法的 宗量 。
根据分派基于多少种宗量,可以将分派划分为单分派和多分派两种。单分派是根据一个宗量对目标方法进行选择,多分派则是根据多于一个宗量对目标方法进行选择。
/**
* 单分派、多分派演示
* @author zzm
*/
public class Dispatch {
static class QQ {}
static class _360 {}
public static class Father {
public void hardChoice(QQ arg) {
System.out.println("father choose qq");
}
public void hardChoice(_360 arg) {
System.out.println("father choose 360");
}
}
public static class Son extends Father {
@Override
public void hardChoice(QQ arg) {
System.out.println("son choose qq");
}
@Override
public void hardChoice(_360 arg) {
System.out.println("son choose 360");
}
}
public static void main(String[] args) {
Father father = new Father();
Father son = new Son();
father.hardChoice(new _360());
son.hardChoice(new QQ());
}
}
在main()里调用了两次hardChoice()方法,这两次hardChoice()方法的选择结果在程序输出中已经显示得很清楚了。
我们关注的首先是 编译阶段 中编译器的选择过程,也就是静态分派的过程。这时候 选择目标方法的依据有两点 :一是静态类型是Father还是Son,二是方法参数是QQ还是360。这次选择结果的最终产物是产生了两条invokevirtual指令,Son的静态类型也是Father,这两条调用指令的参数分别为常量池中指向 Father::hardChoice(360) 及 Father::hardChoice(QQ) 方法的符号引用。因为是根据两个宗量进行选择,所以Java语言的静态分派属于多分派类型。
再看看运行阶段中虚拟机的选择,也就是动态分派的过程。在执行“son.hardChoice(new QQ())”这行代码时,更准确地说,是在执行这行代码所对应的invokevirtual指令时,由于 编译期已经决定目标方法的签名必须为hardChoice(QQ) ,虚拟机此时不会关心传递过来的参数“QQ”到底是“腾讯QQ”还是“奇瑞QQ”,因为 这时候参数的静态类型、实际类型都对方法的选择不会构成任何影响 , 唯一 可以影响虚拟机选择的因素只有该方法的接受者的实际类型是Father还是Son,故最终调用到了实际类型Son类的QQ方法里。因为 只有一个宗量作为选择依据 ,所以Java语言的动态分派属于单分派类型。
JVM动态分派实现
动态分派是执行非常频繁的动作,而且动态分派的方法版本选择过程需要运行时在接收者类型的方法元数据中搜索合适的目标方法,因此,Java虚拟机实现基于执行性能的考虑,真正运行时一般不会如此频繁地去反复搜索类型元数据。面对这种情况,一种基础而且常见的优化手段是为类型在方法区中建立一个 虚方法表 (Virtual Method Table,也称为vtable,与此对应的,在invokeinterface执行时也会用到接口方法表——Interface Method Table,简称itable),使用 虚方法表索引来代替元数据查找以提高性能 。
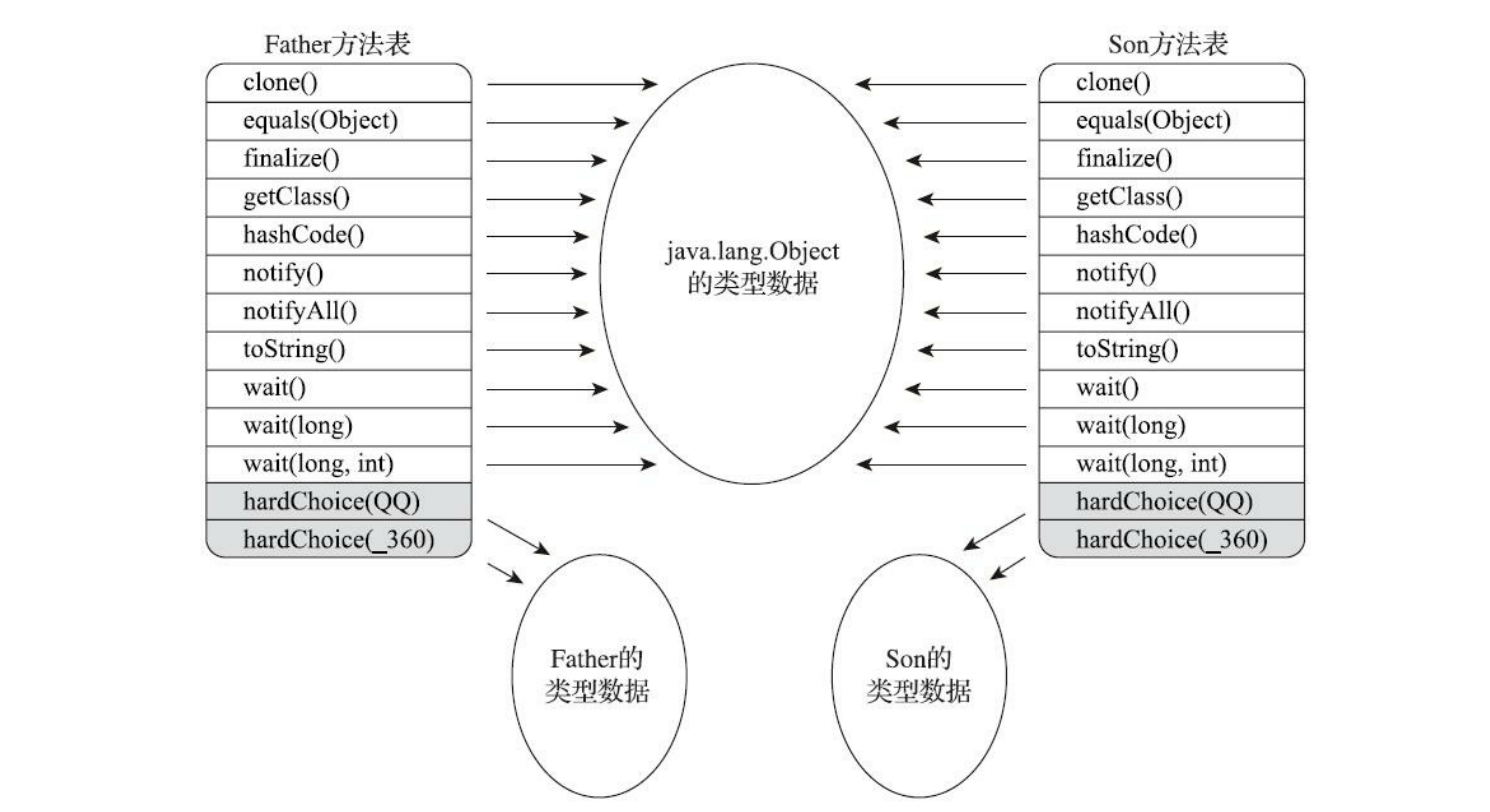
虚方法表中存放着各个方法的实际入口地址。如果某个方法在子类中没有被重写,那子类的虚方法表中的地址入口和父类相同方法的地址入口是一致的,都指向父类的实现入口。如果子类中重写了这个方法,子类虚方法表中的地址也会被替换为指向子类实现版本的入口地址。
为了程序实现方便,具有相同签名的方法,在父类、子类的虚方法表中都应当具有一样的索引序号,这样当类型变换时,仅需要变更查找的虚方法表,就可以从不同的虚方法表中按索引转换出所需的入口地址。虚方法表一般在类加载的连接阶段进行初始化,准备了类的变量初始值后,虚拟机会把该类的虚方法表也一同初始化完毕。
动态类型语言
动态类型语言 的关键特征是它的 类型检查的主体过程是在运行期而不是编译期进行的 ,满足这个特征的语言有很多,常用的包括:APL、Clojure、Erlang、Groovy、JavaScript、Lisp、Lua、PHP、Prolog、Python、Ruby、Smalltalk、Tcl,等等。那相对地,在编译期就进行类型检查过程的语言,譬如C++和Java等就是最常用的静态类型语言。
动态语言面临的难题
前面已经提到过,方法的符号引用在编译时产生,而动态类型语言只有在运行期才能确定方法的接收者。这样,在Java虚拟机上实现的动态类型语言就不得不使用“曲线救国”的方式(如编译时留个占位符类型,运行时动态生成字节码实现具体类型到占位符类型的适配)来实现,但这样势必会让动态类型语言实现的复杂度增加,也会带来额外的性能和内存开销。内存开销是很显而易见的,方法调用产生的那一大堆的动态类就摆在那里。而其中最严重的 性能瓶颈是在于动态类型方法调用时,由于无法确定调用对象的静态类型,而导致的方法内联无法有效进行 。
例如:
var arrays = {"abc", new ObjectX(), 123, Dog, Cat, Car..}
for(item in arrays){
item.sayHello();
}
在动态类型语言下这样的代码是没有问题,但由于在运行时arrays中的元素可以是任意类型,即使它们的类型中都有sayHello()方法,也肯定无法在编译优化的时候就确定具体sayHello()的代码在哪里,编译器只能不停编译它所遇见的每一个sayHello()方法,并缓存起来供执行时选择、调用和内联,如果arrays数组中不同类型的对象很多,就势必会对内联缓存产生很大的压力,缓存的大小总是有限的,类型信息的不确定性导致了缓存内容不断被失效和更新,先前优化过的方法也可能被不断替换而无法重复使用。
这便是JDK 7时JSR-292提案中invokedynamic指令以及java.lang.invoke包出现的技术背景。
方法句柄
JDK 7时新加入的java.lang.invoke包是JSR 292的一个重要组成部分,这个包的主要目的是在之前单纯依靠符号引用来确定调用的目标方法这条路之外,提供一种新的动态确定目标方法的机制,称为“方法句柄”(Method Handle)。
在拥有方法句柄之后,Java语言也可以拥有类似于函数指针或者委托的方法别名这样的工具了。
/**
* JSR 292 MethodHandle基础用法演示
* @author zzm
*/
public class MethodHandleTest {
static class ClassA {
public void println(String s) {
System.out.println(s);
}
}
public static void main(String[] args) throws Throwable {
Object obj = System.currentTimeMillis() % 2 == 0 ? System.out : new ClassA();
// 无论obj最终是哪个实现类,下面这句都能正确调用到println方法。
getPrintlnMH(obj).invokeExact("icyfenix");
}
private static MethodHandle getPrintlnMH(Object reveiver) throws Throwable {
/**
* MethodType:代表“方法类型”,包含了方法的返回值(methodType()的第一个参数)和
* 具体参数(methodType()第二个及以后的参数)。
*/
MethodType mt = MethodType.methodType(void.class, String.class);
/**
* lookup()方法来自于MethodHandles.lookup,这句的作用是在指定类中查找符合
* 给定的方法名称、方法类型,并且符合调用权限的方法句柄。
* 因为这里调用的是一个虚方法,按照Java语言的规则,方法第一个参数是隐式的,
* 代表该方法的接收者,也即this指向的对象,这个参数以前是放在参数列表中进行
* 传递,现在提供了bindTo()方法来完成这件事情。
*/
return lookup().findVirtual(reveiver.getClass(), "println", mt).bindTo(reveiver);
}
}
方法getPrintlnMH()中实际上是模拟了invokevirtual指令的执行过程,只不过它的分派逻辑并非固化在Class文件的字节码上,而是通过一个由用户设计的Java方法来实现。而这个方法本身的返回值(MethodHandle对象),可以视为对最终调用方法的一个“引用”。
仅站在Java语言的角度看,MethodHandle在使用方法和效果上与Reflection有众多相似之处。不过,它们也有以下这些区别:
- Reflection和MethodHandle机制本质上都是在模拟方法调用,但是Reflection是在模拟Java代码层次的方法调用,而MethodHandle是在模拟字节码层次的方法调用。在MethodHandles.Lookup上的3个方法findStatic()、findVirtual()、findSpecial()正是为了对应于invokestatic、invokevirtual(以及invokeinterface)和invokespecial这几条字节码指令的执行权限校验行为,而这些底层细节在使用Reflection API时是不需要关心的。
- Reflection中的java.lang.reflect.Method对象远比MethodHandle机制中的java.lang.invoke.MethodHandle对象所包含的信息来得多。前者是方法在Java端的全面映像,包含了方法的签名、描述符以及方法属性表中各种属性的Java端表示方式,还包含执行权限等的运行期信息。而后者仅包含执行该方法的相关信息。用开发人员通俗的话来讲,Reflection是重量级,而MethodHandle是轻量级。
- 由于MethodHandle是对字节码的方法指令调用的模拟,那理论上虚拟机在这方面做的各种优化(如方法内联),在MethodHandle上也应当可以采用类似思路去支持(但目前实现还在继续完善中),而通过反射去调用方法则几乎不可能直接去实施各类调用点优化措施。MethodHandle与Reflection除了上面列举的区别外,最关键的一点还在于去掉前面讨论施加的前提“仅站在Java语言的角度看”之后:Reflection API的设计目标是只为Java语言服务的,而MethodHandle则设计为可服务于所有Java虚拟机之上的语言,其中也包括了Java语言而已,而且Java在这里并不是主角。
invokedynamic
某种意义上可以说 invokedynamic 指令与MethodHandle机制的作用是一样的,都是为了解决原有4条“invoke*”指令方法分派规则完全固化在虚拟机之中的问题,把如何查找目标方法的决定权从虚拟机转嫁到具体用户代码之中,让用户(广义的用户,包含其他程序语言的设计者)有更高的自由度。而且,它们两者的思路也是可类比的,都是为了达成同一个目的,只是一个用上层代码和API来实现,另一个用字节码和Class中其他属性、常量来完成。