【AI】Deepseek部署内网穿透与Python调用

本文记录了使用Ollama拉取deepseek,使用docker运行包含网页的本地容器进行交互,并使用内网穿透工具进行公网的访问,最后验证了使用Python调用deepseek能力的可行性。
Ollama简介
Ollama 是一个开源项目,是在本地机器上运行 LLM 的强大而友好的平台。它在 LLM 技术的复杂性与人们对可访问、可定制的人工智能体验的渴望之间架起了一座桥梁。
Ollama 的核心功能是简化下载、安装和与各种 LLM 交互的过程,使用户能够探索这些 LLM 的功能,而无需大量的专业技术知识或依赖基于云的平台。
- 本地执行: Ollama 支持大型语言模型的本地运行,为用户提供快速高效的人工智能处理能力。
- 模型定制: 有了 Ollama,您可以自由定制和制作自己的模型,使其成为专业任务的理想选择。
- 用户友好的界面: 该工具的设计确保了易用性,可实现快速、无障碍的设置。 跨平台兼容性: 支持 macOS、Windows 和 Linux。
借助Ollama在本地部署当今主流的开源大模型,包含llama3、gemma、qwen等(其支持的开源大模型可在library (ollama.com)中查看)
安装Ollama
在Windows和MAC平台上可以直接下载安装包进行安装,在Linux平台上可使用以下命令安装:
curl -fsSL https://ollama.com/install.sh | sh
完毕之后可以输入验证:
ollama -h
我是直接在Windows平台上安装的,安装过程比较简单,下载安装包,打开之后直接下一步即可。默认安装在C盘,且自动配置了环境变量,可以直接在cmd里使用 ollama 命令。Ollama默认安装路径为
C:\Users%username%\AppData\Local\Programs\Ollama
如果需要转移到其他盘,安装完毕之后,也可以直接把整个文件夹剪切到其他盘。然后找到ollama自己添加的 PATH 环境变量,将其改为新的地址。
大模型存储地址修改
Ollama 默认下载的大模型存储位置也在C盘,我们需要让其下载到其他地址,也可以自己新建 OLLAMA_MODELS 环境变量,然后将其指向其他地址。
拉取的时候就会自动存储在这个地址下。
Ollama命令行使用
查看本地大模型列表:
C:\Users\stephen>ollama list
NAME ID SIZE MODIFIED
deepseek-coder-v2:16b 63fb193b3a9b 8.9 GB 32 hours ago
deepseek-r1:14b ea35dfe18182 9.0 GB 2 days ago
移除本地大模型:
ollama rm deepseek-r1:14b
创建自定义模型:
ollama create my-model -f my-model.modelfile
启动模型:
ollama run my-model
停止模型:
ollama stop my-model
更新模型
C:\Users\stephen>ollama pull deepseek-r1:14b
pulling manifest
pulling 6e9f90f02bb3... 100% ▕███████████████▏ 9.0 GB
pulling 369ca498f347... 100% ▕███████████████▏ 387 B
pulling 6e4c38e1172f... 100% ▕███████████████▏ 1.1 KB
pulling f4d24e9138dd... 100% ▕███████████████▏ 148 B
pulling 3c24b0c80794... 100% ▕███████████████▏ 488 B
verifying sha256 digest
writing manifest
success
显示模型信息:
C:\Users\stephen>ollama show deepseek-coder-v2:16b
Model
architecture deepseek2
parameters 15.7B
context length 163840
embedding length 2048
quantization Q4_0
Parameters
stop "User:"
stop "Assistant:"
License
DEEPSEEK LICENSE AGREEMENT
Version 1.0, 23 October 2023
拉取deepseek-r1
拉取模型的过程极致的简单,只需要执行以下命令即可:
ollama run deepseek-r1:14b
末尾是指定的训练参数大小, deepseek 提供了7b,14b,32b等等选项。
14b大小为9G,我体验的话下载应该是无限速,中途下载速度如果变慢了,可以Ctrl C掐断后,立即重新开始,就会重置下载速度,也不会断传。
拉取完整性检验完毕之后,会直接打开deepseek的对话命令行,可以直接跟其进行交互。使用Ctrl D可以退出对话。
C:\Users\stephen>ollama run deepseek-r1:14b
>>> 介绍一下你自己
<think>
</think>
您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。
测试一个简单的Python编程需求:
>>> 使用python怎么执行本地命令行
<think>
嗯,用户问我“使用python怎么执行本地命令行”。这看起来是一个关于Python编程的问题,具体涉及到如何在Python中执行本地的
命令行指令。
首先,我需要理解用户的需求。他可能想要在自己的Python脚本中运行一些系统命令,比如ls、cd或者其他任何可以在终端中运行的
命令。这可能是因为他在进行自动化任务,或者想让脚本执行一些依赖于系统命令的操作。
接下来,我要考虑有哪些Python库可以用来执行命令行指令。我知道有几个常用的模块,比如os和subprocess。这两个模块都可以用
来调用外部程序,并且能够获取它们的输出或错误信息。
对于os模块来说,它有一个system()函数,可以直接运行命令,但返回的结果比较有限,主要是用于执行命令本身。而subprocess模
块则更为强大,因为它不仅可以运行命令,还可以捕捉标准输出和错误输出,处理进程的终止等等。
我需要决定推荐哪个库更好。考虑到功能性和灵活性,subprocess模块可能更适合大多数情况,尤其是当用户需要捕获命令的输出或
者处理更复杂的任务时。然而,os.system()在简单的场景下使用起来更为简单直观。
另外,我还需要考虑用户可能的使用场景。如果他只是想运行一个简单的命令,并不需要获取输出或错误信息,那么os.system()可
能足够了。但如果他需要更多的控制和反馈,比如处理返回值或者错误情况,subprocess会是更好的选择。
我应该提供两种方法的例子,让用户可以根据自己的需求来选择。这样既展示了基本的使用方法,也提供了更高级的功能实现。
此外,我还应该强调最佳实践的重要性。例如,在执行外部命令时,使用shell=True可能会带来一定的安全风险,比如命令注射攻击
。因此,如果可能的话,建议用户通过传递参数列表的方式调用命令,而不是直接拼接字符串。这样可以减少潜在的安全漏洞。
最后,我要确保解释清晰易懂,避免过于技术化的术语,让用户能够轻松理解并应用这些方法到自己的项目中。
</think>
在 Python 中,如果你想执行本地的命令行指令(例如 ls, cd, echo 等),可以通过以下几种方式实现。以下是常用的方法
:
1. 使用 os.system()
os 模块提供了一个简单的方法来执行系统命令。
示例代码:
import os
# 执行 "dir" 命令(Windows)或 "ls" 命令(Linux/macOS)
os.system("dir") # Windows
# 或者
os.system("ls") # Linux/macOS
输出:
这会直接在终端中执行命令,并输出结果到标准输出。
2. 使用 subprocess 模块
subprocess 是更强大和灵活的模块,推荐用于复杂的任务。它允许你捕捉输出、处理错误以及管理进程。
示例代码(运行命令并获取输出):
import subprocess
# 执行 "ls" 命令,并将结果存储在变量中
result = subprocess.run("ls", capture_output=True, text=True)
print(result.stdout) # 输出命令的 stdout
更复杂的用法:
import subprocess
# 使用 shell=True 可以执行更复杂的命令(不推荐用于外部输入,有安全风险)
result = subprocess.run(
"echo Hello World",
shell=True,
capture_output=True,
text=True
)
print(result.stdout) # 输出 "Hello World"
3. 使用 os.popen()
os.popen() 可以打开一个管道,方便地读取命令的输出。
示例代码:
import os
# 执行命令并获取输出
output = os.popen("ls").read()
print(output)
注意事项
安全性:如果使用 subprocess.run() 的 shell=True,可能会带来安全风险(例如命令注入攻击)。因此,在处理用户输入时,尽量避免这种方式。
平台兼容性:某些命令可能只在特定平台上可用。例如,ls 是 Unix 系统的命令,而 dir 是 Windows 的命令。
总结
如果需要简单的命令执行,可以使用 os.system()。
如果需要更灵活和强大的功能(比如捕获输出、处理错误),推荐使用 subprocess 模块。
希望这些方法能帮到你!
安装Open WebUI
手动安装wsl
我的电脑是win10企业版,没有微软商店,也不带wsl子系统,需要手动安装。可以直接参考微软的官方文档。
首先启用两个功能,使用 管理员权限 打开power shell。
- 启用适用于 Linux 的 Windows 子系统:
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
- 启用虚拟机平台:
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
然后重启电脑。
安装完成后,将wsl2设为默认版本:
wsl --set-default-version 2
安装Docker
使用 Docker 来部署运行 Open WebUI 是一种简单而有效的方法,可以用一个交互友好的界面来使用Deepseek。
docker pull ghcr.io/open-webui/open-webui:main
下载完毕之后,在运行该项目前请确保部署在 Ollama 中的语言模型处于运行状态。
然后在Docker中的Terminal终端中输入并执行以下命令:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
启动成功后,也可以通过Docker Desktop来进行管理:
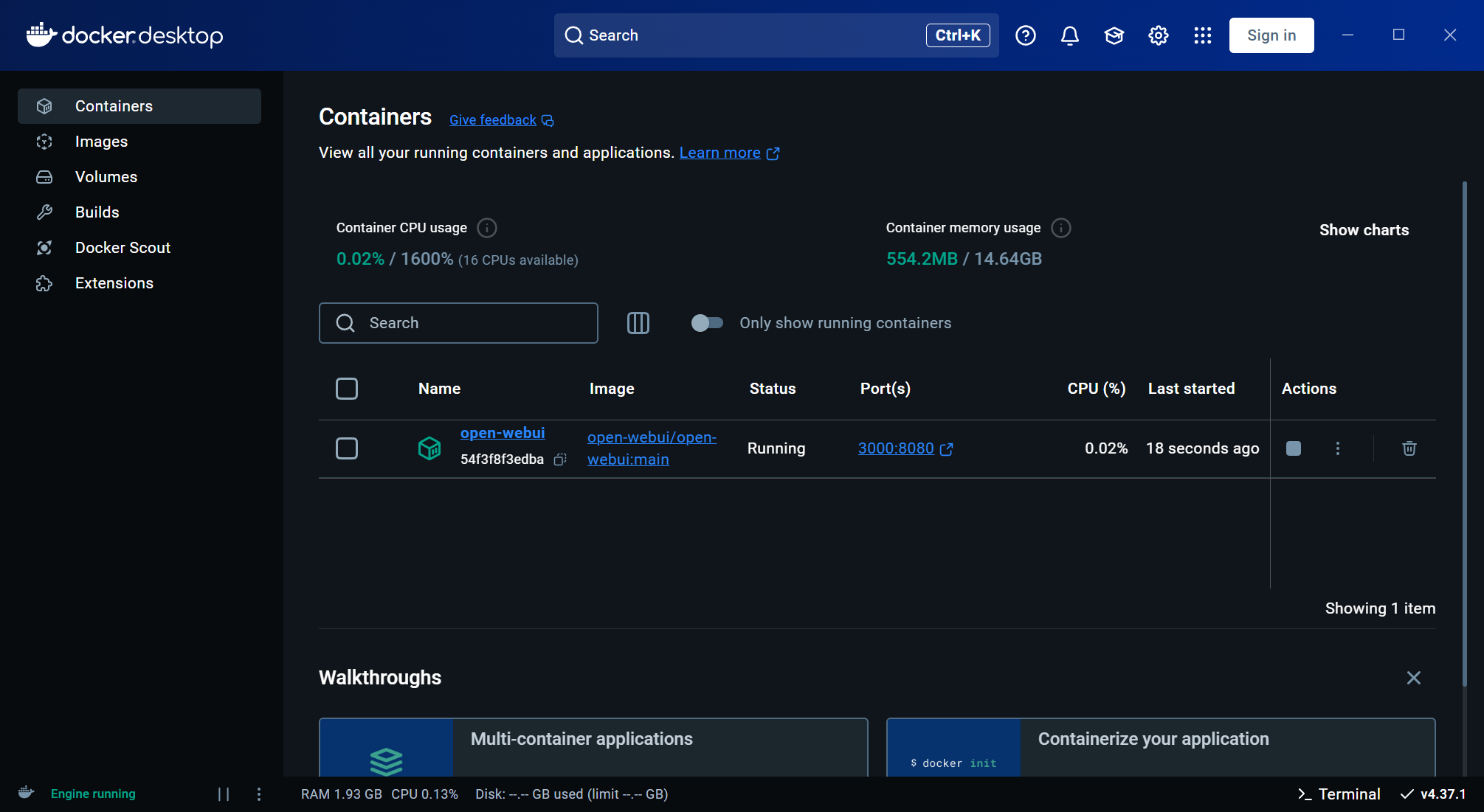
打开浏览器,转到 http://localhost:3000/ ,进行聊天测试。初次进入需要设置 管理员账户 ,在后台就可以对模型的访问进行一系列的设置。
内网穿透出去
如果想在公司内部小范围使用,或者不在电脑边,想使用手机访问deepseek,可以使用内网穿透工具,这里推荐使用 cpolar 。
cpolar官网地址: https://www.cpolar.com
注册账号,登录后,选择免费套餐,下载 cpolar 安装包,下载完毕打开,一直点下一步即可。
安装完毕后,浏览器打开本地localhost的 9200 端口:
http://localhost:9200
使用自己刚刚注册的账号登录之后,在cpolar左侧导航栏中,点击 隧道管理 ,然后点击 添加隧道 ,选择 HTTP 协议,本地地址设置为 OpenWebUI 的 3000 端口
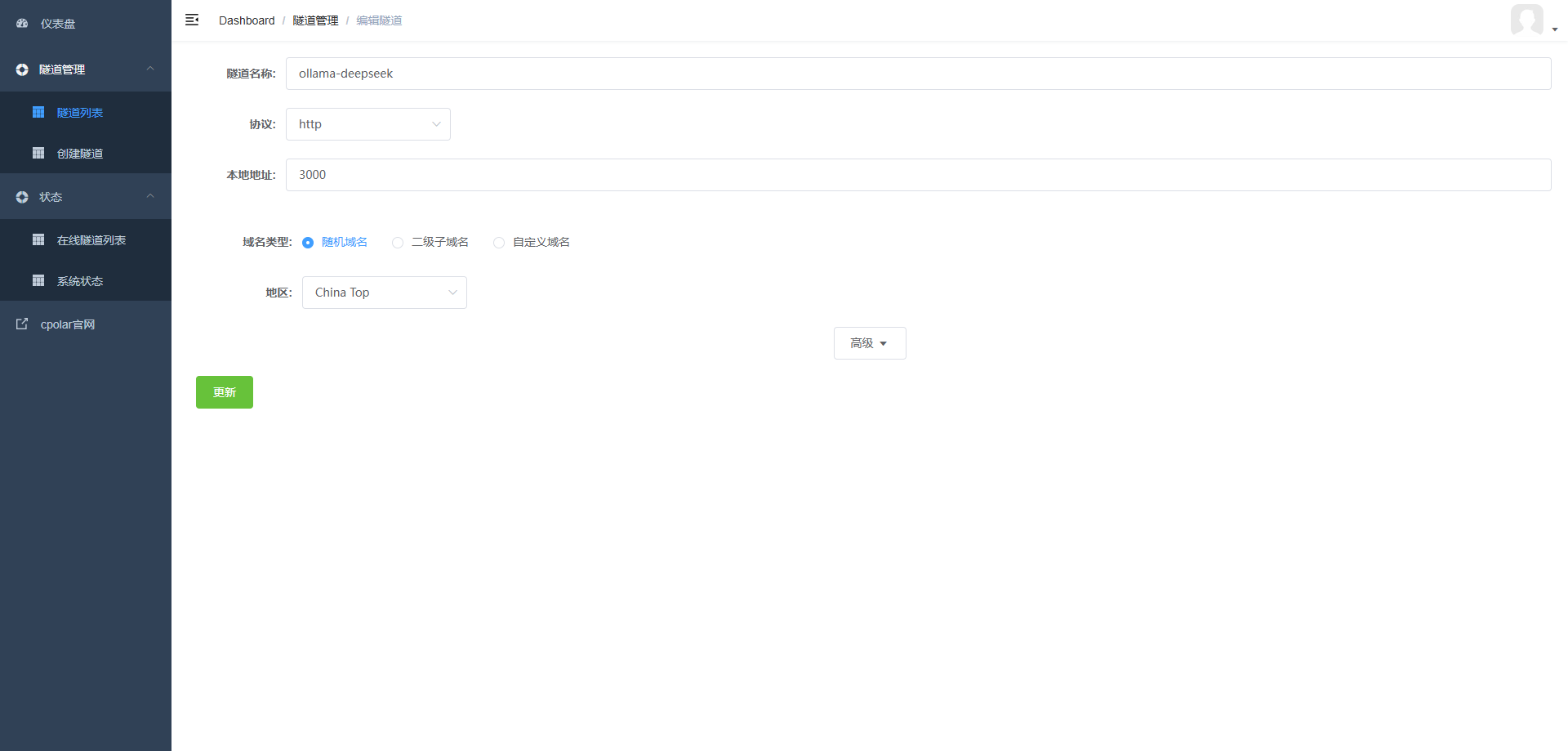
配置完成之后,点击 创建 ,等待cpolar分配一个域名。
然后点击 状态 ,里面有一个 在线隧道列表 将显示的域名复制到浏览器中,打开即可。
需要注意的是,刚才创建的是随机地址,24小时会发生变化。另外它的网址是由随机字符生成,不容易记忆。如果想把域名变成固定的二级子域名,并且不想每次都重新创建隧道来访问Open WebUI,我们可以选择创建一个固定的公网地址来解决这个问题。想要创建保留域名,需要开通Cpolar的会员,这个后面再看看。
Open WebUI的用户配置
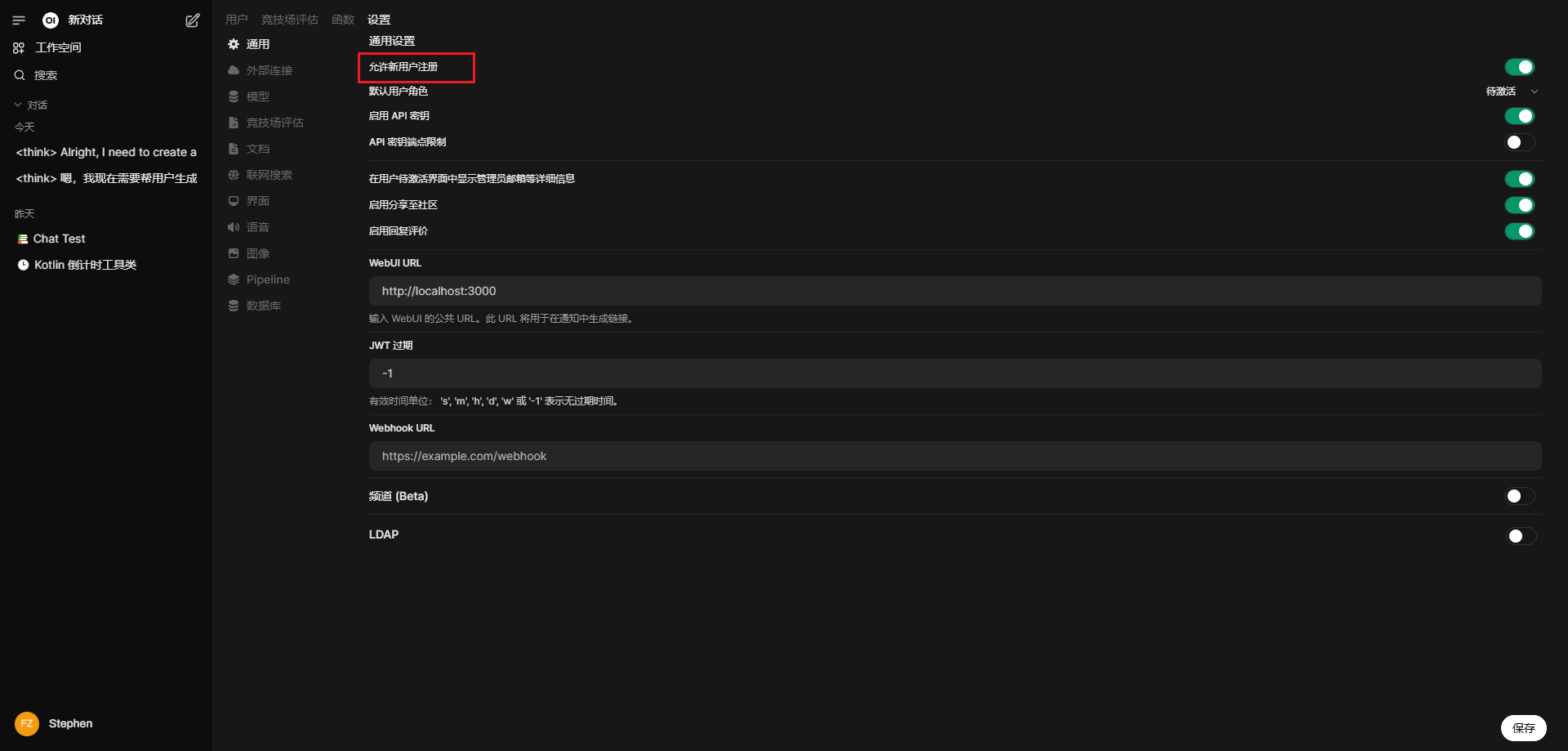
使用外部的公共链接,首次打开后,发现没有注册新用户账号的地方,只能登录管理员账号使用,这是因为Open WebUI默认是不允许用户注册的。
探索之后发现,可以先使用oi的管理员账户登录,然后在设置里面找到,开启允许新用户注册:
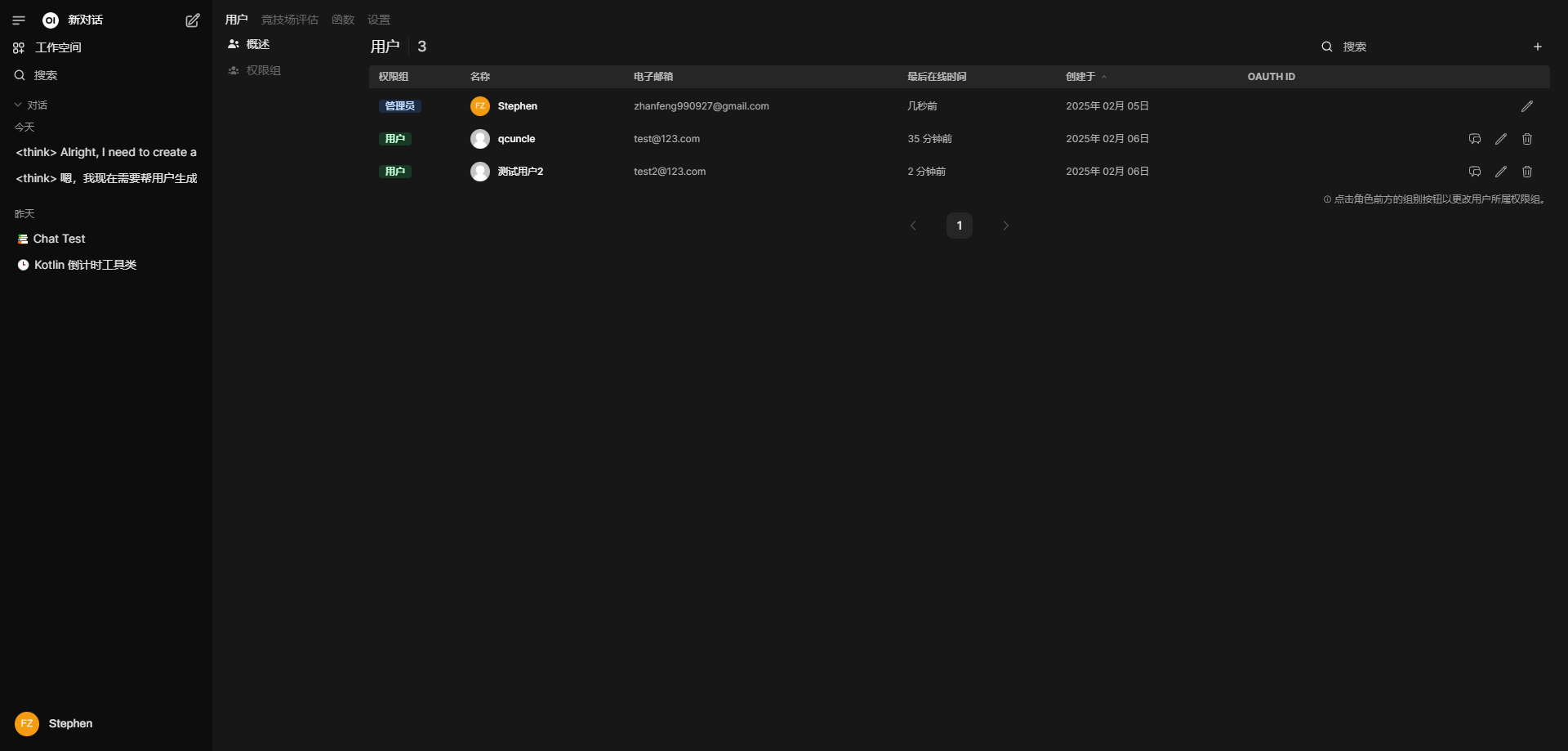
或者直接在管理员后台,像下面这样点加号手动创建几个新账号来使用:
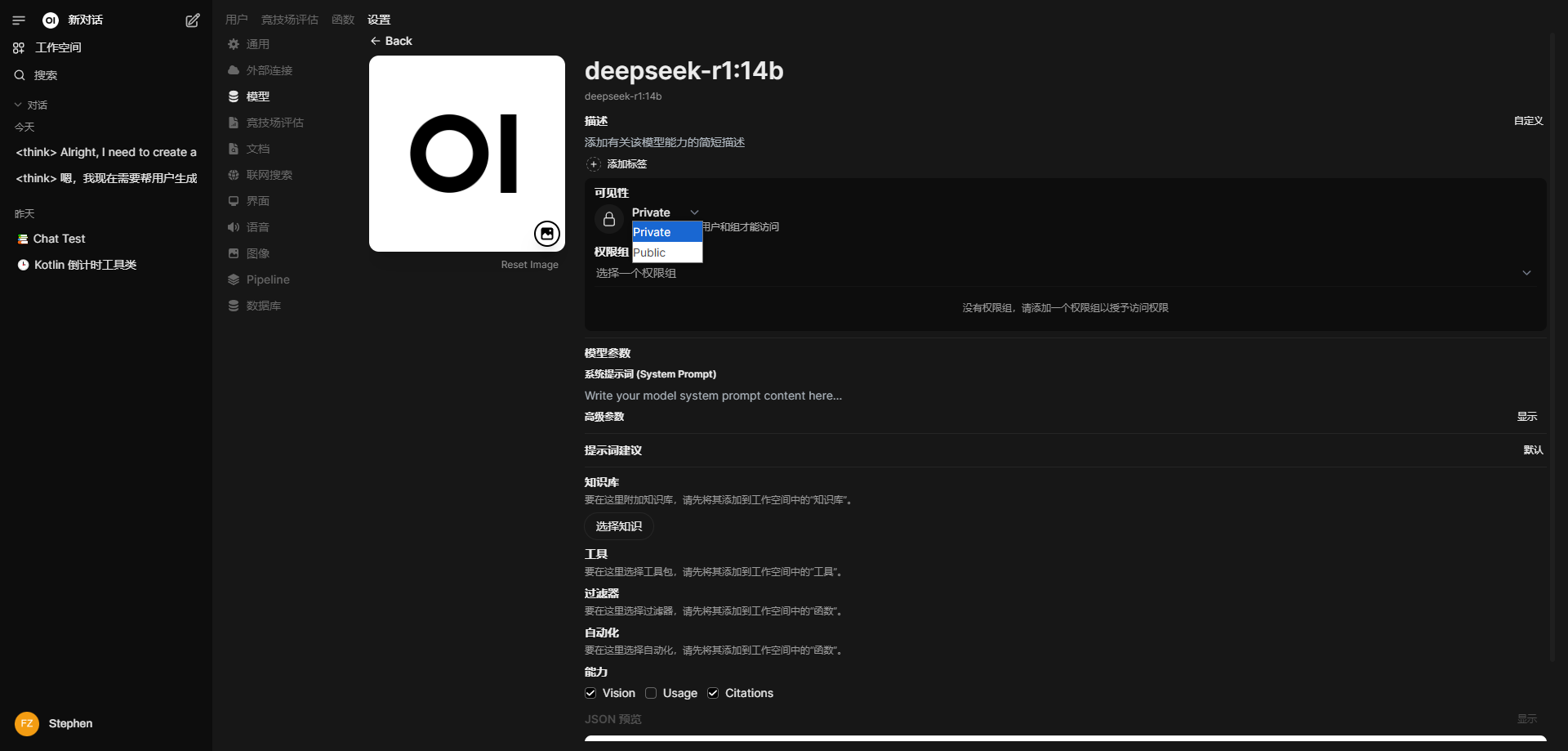
最后将对应模型的可见性设置为public公开,让非管理员用户也可以使用:
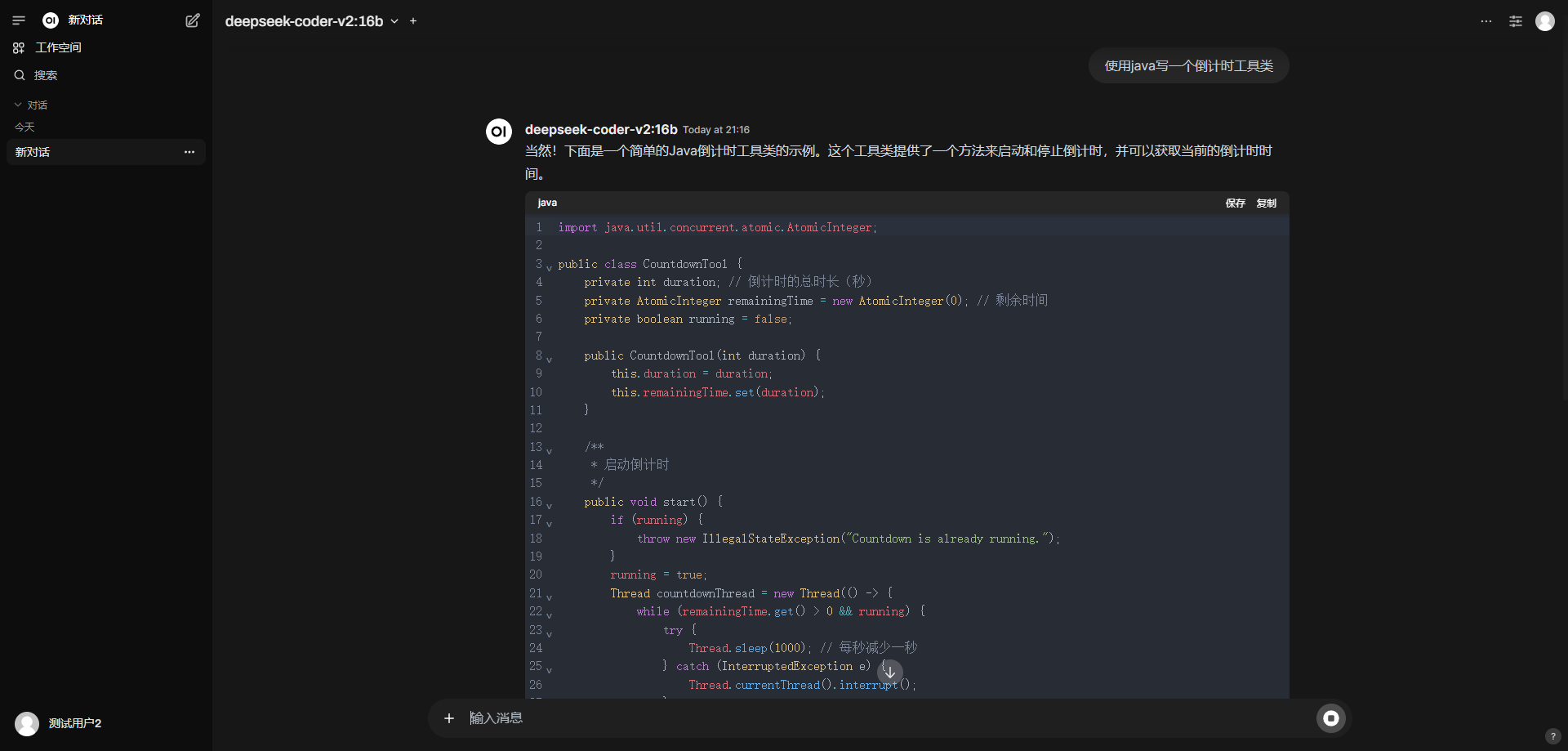
配置完成测试,使用普通账号登录之后,可以正常使用模型了,就像下面这样:
使用Python调用Deepseek的能力
对于程序开发来说,如果只是在用户层面使用UI交互,那局限性太大了,能不能使用AI的能力,来优化一些程序运行结果呢?
最近做了一个翻译的小项目,将本地的中文的 strings.xml 翻译成英文的,输出到项目中集成,完成英文界面的显示需要。
目前是用本地词条数据库加上百度,网易,阿里的翻译api来实现的,但是有一个问题,就是机器翻译的结果不是很准确,所以想能不能使用 Deepseek 来优化一下。
github发现 ollama 有官方的 Python 库了.
https://github.com/ollama/ollama-python
导入之后,可以直接使用 chat 接口调用到本地部署的模型的能力。配置好model名称,再输入 message 即可。
官方样例
from ollama import chat
from ollama import ChatResponse
response: ChatResponse = chat(model='llama3.2', messages=[
{
'role': 'user',
'content': 'Why is the sky blue?',
},
])
print(response['message']['content'])
# or access fields directly from the response object
print(response.message.content)
运行结果:
The sky appears blue because of a phenomenon called Rayleigh scattering. When sunlight reaches Earth’s atmosphere, it is made up of many different colors, each with different wavelengths. The shorter wavelengths, such as blue and violet light, are scattered in all directions by the gases and small particles in the atmosphere. Since our eyes are more sensitive to blue than violet, we perceive the sky as blue. During sunrise or sunset, the sun is closer to the horizon, so the light has to pass through more atmosphere, scattering out the shorter wavelengths and allowing the longer red and orange wavelengths to dominate, creating the colorful skies during these times.
本地翻译项目测试
import ollama
def translate_test():
res = ollama.chat(model='deepseek-r1:14b', stream=False,
messages=[{'role': 'user',
'content': '假如你是一个汽车领域的翻译专家,帮我翻译下面的几个词条:驾驶模式,智能驾驶,座椅加热,语音助手'}])
print(res['message']['content'])
translate_test()
结果打印:
当然可以!以下是这几个词条的翻译:
1. 驾驶模式 - Driving Mode
2. 智能驾驶 - Intelligent Driving
3. 座椅加热 - Heated Seats
4. 语音助手 - Voice Assistant
这些翻译在汽车领域中是常见的表达方式,希望对你有帮助!
可以看到使用 deepseek 的翻译质量上比在线的机器翻译要好上不少。
但是还需要将 AI 的回复进行二次处理,才能得到最终的结果,结合到程序流程中去。输出处理后的格式一旦对不上,程序的运行流程就会出错。目前仅仅是验证了一下可行性,还未正式使用。
流式输出
除了同步返回外,也支持流式输出:
from ollama import chat
stream = chat(
model='llama3.2',
messages=[{'role': 'user', 'content': 'Why is the sky blue?'}],
stream=True,
)
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)
结果打印:
<think>
</think>
The sky appears blue due to a phenomenon known as Rayleigh scattering. When sunlight reaches Earth's atmosphere, it interacts with molecules and small particles in the air. Sunlight is composed of various colors, each corresponding to different wavelengths. Blue light has a shorter wavelength and is scattered more by these tiny particles, whereas other colors like red or orange are scattered less. As a result, blue light is dispersed across the sky, making it appear blue to our eyes. This scattering effect is named after Lord Rayleigh, who explained it in the 19th century.
Process finished with exit code 0
异步请求
最后介绍下ollama库的异步请求。
AsyncClient 类用于发出异步请求。它可以配置与客户端类相同的字段。
import asyncio
from ollama import AsyncClient
async def chat():
message = {'role': 'user', 'content': 'Why is the sky blue?'}
response = await AsyncClient().chat(model='llama3.2', messages=[message])
asyncio.run(chat())
设置 stream=True 会修改函数,使其返回 Python 异步生成器:
import asyncio
from ollama import AsyncClient
async def chat():
message = {'role': 'user', 'content': 'Why is the sky blue?'}
async for part in await AsyncClient().chat(model='llama3.2', messages=[message], stream=True):
print(part['message']['content'], end='', flush=True)
asyncio.run(chat())
以上就是对 ollama-python 库的简要使用介绍。
云端服务 API 参数含义
在使用Deepseek和Kimi等厂商提供的云端大模型服务时,在api文档中,可以看到请求的参数有很多。这些常见的参数代表什么含义呢?
举例:
curl -L -X POST 'https://api.deepseek.com/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Accept: application/json' \
-H 'Authorization: Bearer <TOKEN>' \
--data-raw '{
"messages": [
{
"content": "You are a helpful assistant",
"role": "system"
},
{
"content": "Hi",
"role": "user"
}
],
"model": "deepseek-chat",
"frequency_penalty": 0,
"max_tokens": 4096,
"presence_penalty": 0,
"response_format": {
"type": "text"
},
"stop": null,
"stream": false,
"stream_options": null,
"temperature": 1,
"top_p": 1,
"tools": null,
"tool_choice": "none",
"logprobs": false,
"top_logprobs": null
}'
- messages - 消息列表,每个消息包含角色(role)和内容(content)。角色可以是 “system”、”user” 或 “assistant”。
- model - 模型名称,例如 “deepseek-chat”。
- frequency_penalty - 频率惩罚,用于控制模型生成重复内容的程度。介于 -2.0 和 2.0 之间的数字。如果该值为正,那么新 token 会根据其在已有文本中的出现频率受到相应的惩罚,降低模型重复相同内容的可能性。即值越高,模型越倾向于生成不同的内容。
- max_tokens - 最大的token数量,用于限制模型生成的响应长度。
- presence_penalty - 存在惩罚,用于控制模型生成新内容的程度。值越高,模型越倾向于生成新的内容。
- response_format - 响应格式,例如 “text” 或 “json”。
- stop - 停止序列,用于指定模型在生成响应时何时停止。可以是一个字符串或字符串列表。
- stream - 是否流式输出,默认为 false。如果设置为 True,将会以 SSE(server-sent events)的形式以流式发送消息增量。消息流以
data: [DONE]结尾。 - temperature - 采样温度,介于 0 和 2 之间。更高的值,如 0.8,会使输出更随机,而更低的值,如 0.2,会使其更加集中和确定。 我们通常建议可以更改这个值或者更改 top_p,但不建议同时对两者进行修改。
- top_p - nucleus sampling 概率阈值,介于 0 和 1 之间。模型会根据其概率分布生成下一个 token,而 top_p 则会限制模型只考虑概率最高的前 p% 的 token。例如设置为 0.1 就意味着只有包括在最高 10% 概率中的 token 会被考虑。
- tools - 工具列表,用于指定模型可能会调用的 tool 的列表。目前,仅支持 function 作为工具。使用此参数来提供以 JSON 作为输入参数的 function 列表。最多支持 128 个 function。
- tool_choice - 工具选择,用于指定模型应该使用哪个工具。可以是 “none”、”auto” 或工具名称。
- logprobs - logprobs 参数让你可以查看模型在生成每个词(token)时,它认为各个候选词的“可能性”有多大,并以一种数学上更优的形式——对数概率——返回给你。如果为 true,则在 message 的 content 中返回每个输出 token 的对数概率。
temperature和top_p实现调控的区别
temperature
temperature 像一个“软化剂”或“锐化剂”,它直接作用于所有词语的概率分布。
- 值越高 (比如 1.0): 它会“软化”概率分布,让那些本来概率很低的词语(比如“桌子”的 5%)的权重提高,变得更有可能被选中。这样模型的选择范围就扩大了,输出会更加随机和有创意。
- 值越低 (比如 0.2): 它会“锐化”概率分布,让高概率的词语(比如“苹果”的 50%)的权重更加突出。模型会更倾向于选择最安全、最确定的词语,输出会更保守、更重复。
改变 temperature 就像是在调整整个概率曲线的形状,影响了所有词语被选中的相对可能性。
top_p
top_p 则是一个“概率预算”,它通过限制可选词语的数量来控制随机性。
模型会按概率从高到低排序,然后选择一个最小的词语集合,使得这些词语的累积概率达到你设置的 top_p 值。模型后续的选择只会从这个被“裁剪”的集合中进行。如果你设置 top_p=0.9,模型会选出那些加起来概率达到 90% 的词语,将完全排除概率很低的词语。
- 值越高 (比如 0.9): 预算更大,模型可选的词语更多,输出更多样。
- 值越低 (比如 0.1): 预算很小,模型只能选择最有可能的少数几个词,输出更保守。
改变 top_p 就像是在概率列表上画一条线,直接淘汰掉那些累积概率达不到预算的词语。
调参的经验法则
对于需要事实准确、代码或总结的严谨任务,将 temperature 设置为 0.0 到 0.5 左右,或将 top_p 设置为 0.95 或更高(基本上只依赖概率)。
对于需要创意、故事或头脑风暴的任务,将 temperature 设置为 0.7 到 1.0 左右,或将 top_p 设置为 0.8 到 0.9。