【AI】激活函数

本文介绍了若干种常见的AI领域的算法及其应用场景
简单来说,激活函数的主要作用是 向神经网络中引入非线性因素 。可以将激活函数理解为神经网络中一个至关重要的“开关”和“调节器”。它被 应用在每个神经元的输出 上,用来决定这个神经元应该在多大程度上被“激活”,以及它应该向下一层传递多强的信号。
在人工神经网络中,一个神经元会接收来自上一层的多个输入信号。它会首先将这些输入信号进行 “加权求和” ,并加上一个 偏置项 。
这个加权求和的结果是一个线性的值。 \[z = \sum(weight \cdot input) + bias\]
激活函数 f(z) 就是紧接着应用在这个线性结果 z 上的一个非线性函数。它会产生该神经元的最终输出 a = f(z) ,这个输出 a 随后会作为输入传递给网络的下一层。
这一点至关重要。想象一下,如果没有激活函数会发生什么?
- 每一层的输出都只是上一层输入的线性组合。
- 无论你堆叠多少层神经网络,整个网络的最终输出也仍然只是最开始输入的线性组合。
- 这样的网络,无论多深,其能力都等同于一个单层的线性模型(比如线性回归或逻辑回归)。
- 它将完全无法学习和拟合现实世界中复杂的非线性关系(例如图像识别、语音识别等)。
激活函数 被应用到每个神经元的输出上,对加权求和后的结果进行一次 非线性变换 。正是这种非线性变换,使得神经网络能够:
- 拟合复杂模式:能够学习和逼近几乎任何复杂的非线性函数,从而处理像图像识别、自然语言处理这样复杂的问题。
- 增强网络能力:赋予了网络更强的表达能力,使其能够区分和学习那些线性模型无法区分的数据特征。
- 控制输出范围:某些激活函数(如 Sigmoid)可以将输出值压缩到特定范围内(例如 0 到 1),这在特定任务中(如概率预测)非常有用。
反向传播
正向传播和反向传播是神经网络训练过程中相辅相成的两个阶段。
正向传播 (Forward Propagation)是模型进行预测的过程。数据从输入层“正向”流到输出层,得出一个预测结果。
反向传播 (Backpropagation)是模型学习和修正错误的过程。根据预测结果和真实答案之间的“误差”,从输出层 “反向”计算每个权重参数(W)应该如何调整 。
一个生动的比喻是学生考试和老师批改:
- 正向传播过程:你(模型)拿到考卷(输入数据),凭你当前的知识(权重 W),从第一题做到最后一题,最后给出一个完整的答案(预测值)。
- 反向传播:老师(算法)拿到你的答案,和标准答案(真实标签)进行对比,计算出你错得有多离谱(计算损失 L)。然后,老师从最后一题开始,反向分析:“你这道题错了(输出层的梯度),是因为你上一步的这个公式用错了,而这个公式用错,又是因为你最开始的那个定义就没背对(更早隐藏层的梯度)…”。老师就这样一步步 把“错误”的责任分摊 给你知识体系中的每一个知识点(W),并告诉你每个知识点具体该怎么修正,这就是:
损失函数(L)对权重(W)的偏导数
\[\frac{\partial L}{\partial W}\]的意思是 “损失函数(L)”对“权重(W)”的偏导数。
它代表的是 “梯度”(Gradient) ,用来衡量 “当权重 W 发生一个极小的变化时,损失 L 会相应地发生多大变化” 。
这个值是神经网络训练(“学习”)的根本依据。
- L:代表损失函数 (Loss Function)
- “损失”是一个数字,它用来衡量你的模型(比如一个神经网络)预测得有多“糟糕”。
- 如果 L 很大,说明模型预测的结果和真实答案相差很远。
- 如果 L 很小(接近0),说明模型预测得非常准确。
- 训练模型的目标,就是最小化这个 L 值。
- W:代表权重 (Weights)
- “权重”是神经网络中的参数。你可以把它们想象成网络中神经元之间连接的“强度”。
- 模型如何从输入得到最终的预测结果,完全是由这些 W 值决定的。
- 模型“学习”的过程,实际上就是不断调整和优化所有 W 值的过程。
代表偏导数 (Partial Derivative),在神经网络中,L(损失)的值是 由成千上万个不同的 W(权重)共同决定的 。
偏导数的作用就是,单独衡量 L 是如何受到某一个特定权重 W 影响的。它在问一个问题:“如果我们只把这一个 W 增加一点点,同时保持所有其他权重不变,那么 L 会增加还是减少?变化的幅度有多大?”
详细解释“反向传播”
反向传播的目标是计算出每个权重 W 到底对最终的“错误”负有多大责任,即计算梯度 \[\frac{\partial L}{\partial W}\]
以便在下一步更新它们。
数据(梯度)流向是从 输出 -> 隐藏层 -> 输入 。
损失函数和权重的偏导数它通常和梯度下降(Gradient Descent) 算法协同工作。
- 计算损失 (Loss):
- 首先,我们比较模型的预测值(来自正向传播)和真实答案(即标签)。
- 使用损失函数 L(例如交叉熵)来计算出一个分数,这个分数代表模型“错得有多离谱”。
- 计算输出层的梯度:
- 反向传播从 L 开始。
- 它首先计算 L 相对于最后一层的权重 W_last 的偏导数。这告诉我们 最后一层的 W 应该如何调整。
利用“链式法则”反向传播: 这是最关键的一步。算法使用微积分中的 链式法则 ,将“错误梯度” 从后一层反向传播到前一层。它会计算: \[\frac{\partial L}{\partial W_{\text{hidden}}}\]
这个计算会依赖于它后面一层(即
W_last)的梯度。这个过程就像在说:“最后一层对错误负有 X 的责任,而你(当前层)对最后一层的输出负有 Y 的责任,所以你对总错误负有 X · Y 的责任。”这个过程一直重复,直到计算出网络中 每一个 W 对应的偏导数 。
更新所有权重(梯度下降步骤): 一旦反向传播计算出了所有 W 的梯度,优化器(如梯度下降)就会使用这个信息来更新所有的 W。更新公式: \[W_{\text{new}} = W_{\text{old}} - \text{learning\_rate} \cdot \frac{\partial L}{\partial W}\]
(减去梯度,是因为梯度指向 L 增加最快的方向,所以我们要朝相反方向去最小化 L)。
一句话总结:反向传播是模型在“复盘”或“订正错误”,它找出每个 W 犯了多少错,并告诉 W 应该朝哪个方向改正。
激活函数分类和优缺点
以下是几种最常用和最重要的激活函数,包括它们的公式、特点以及优缺点。激活函数分类图表:
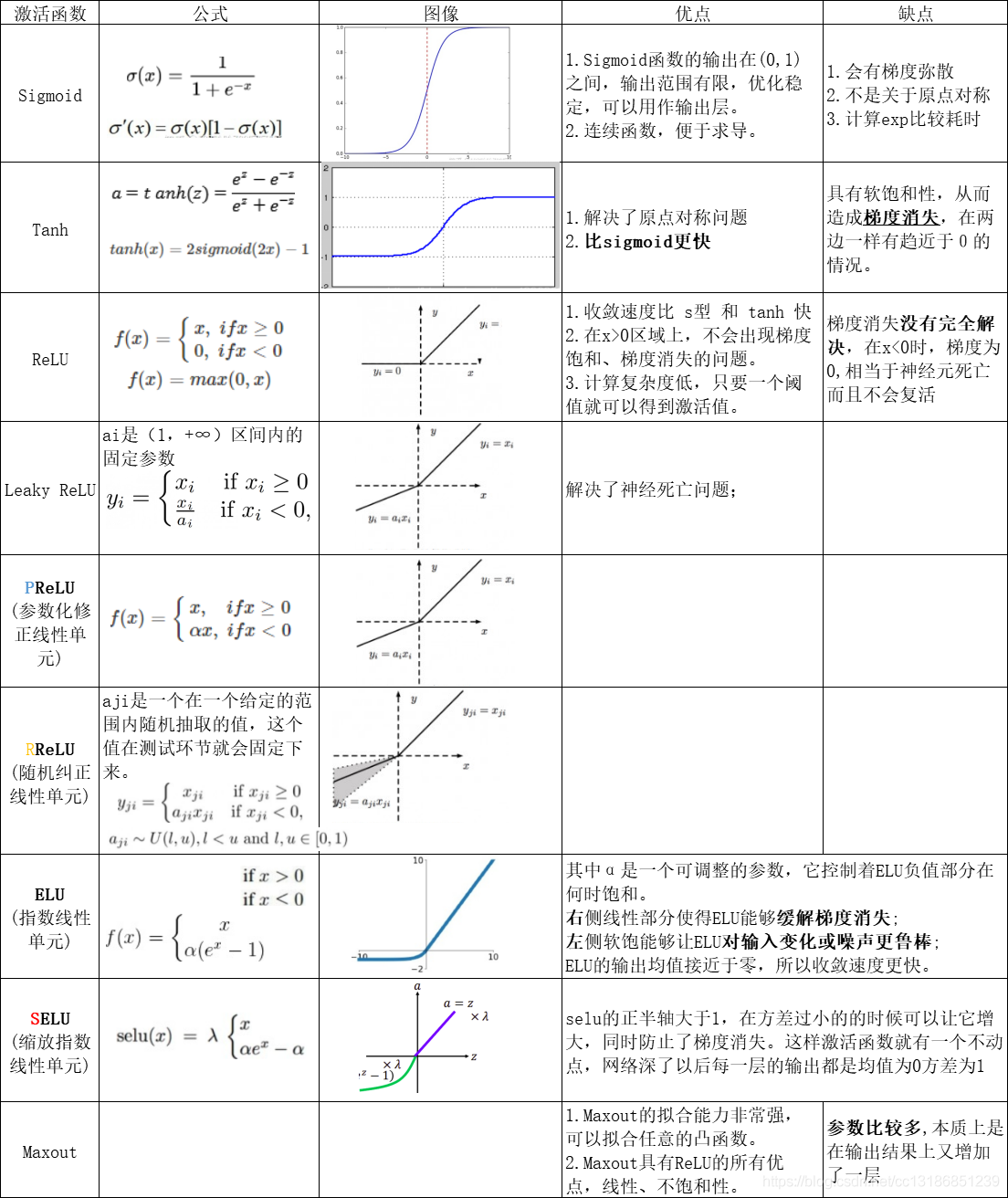
1. Sigmoid (Logistic) 函数
对应的数学模型也叫 逻辑回归 模型,公式: \[f(x) = \frac{1}{1 + e^{-x}}\]
它能将输入值“压缩”到 0 和 1 之间,输出平滑且易于求导。在早期神经网络中很流行,常用于二元分类任务的输出层(输出概率)。
缺点:
- 梯度消失:当输入值非常大或非常小时,函数的导数(梯度)趋近于 0。在反向传播过程中,误差(损失)的梯度需要从输出层一路“传播”回输入层,以便更新每一层的权重。梯度消失就是指,在传播过程中,梯度信号变得越来越小,当传到网络的浅层(靠近输入的层)时,梯度已经小到几乎为零。
- 输出非零中心:输出始终为正数(0到1),这会导致后续网络层的输入是非零均值的,这使网络的收敛速度变慢,可能降低训练效率。
- Sigmoid 的输出:始终在 (0, 1) 区间,恒为正数。
- 对下一层的影响:在反向传播中,某一层的权重 W 的梯度,会包含来自上一层的输入 x(即 Sigmoid 的输出)。
由于 x(Sigmoid 的输出)始终为正,导致偏导数的 所有分量的符号(正或负)都完全取决于上游梯度 。
这会导致权重在更新时,要么 所有的权重都一起增加,要么所有的权重都一起减小 。这限制了梯度下降的寻优路径,使其只能呈“Z”字形(ZigZag)下降,收敛效率低下。
相比之下, Tanh (输出为 -1 到 1,零中心)在这个问题上表现更好。而 ReLU ( f(x) = max(0, x) )则极大地解决了另外一个梯度消失问题(在正区间,导数恒为 1),因此成为了现在最主流的激活函数。
2. Tanh (双曲正切) 函数
公式: \[f(x) = \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}\]
它将输入值“压缩”到 -1 和 1 之间。与 Sigmoid 相比,它的 输出是零中心 的(均值为 0),这通常能带来更快的收敛速度。
缺点是仍然存在 梯度消失 的问题,当输入值饱和时(接近 -1 或 1),梯度也会趋近于 0。
3. ReLU (Rectified Linear Unit, 修正线性单元)
公式: \[f(x) = \max(0, x)\]
解决了梯度消失(在正区间):当输入 x > 0 时,导数恒为 1,这极大地缓解了梯度消失问题,使得训练深度网络成为可能。
计算非常简单(只是一个阈值判断),比 Sigmoid 和 Tanh 的指数运算快得多。
当输入 x < 0 时,输出为 0,这能使网络中的一些神经元“关闭”,带来稀疏性,可能 有助于提取特征和防止过拟合 。
缺点是 Dying ReLU(神经元死亡) 如果一个神经元的输入在训练过程中始终为负数,那么它的输出将永远是 0,梯度也永远是 0。这个神经元将停止学习和更新。
4. Leaky ReLU (LReLU, 泄露型 ReLU)
公式: \[f(x) = \max(\alpha x, x)\]
(其中 alpha 是一个很小的常数,如 0.01)
为了解决 “Dying ReLU” 神经元死亡问题而设计。当输入 x < 0 时,它不再输出 0,而是 输出一个非常小的正值 (如 0.01x),从而保证了在负区间的梯度不为零。
PReLU(Parametric ReLU) 是 Leaky ReLU 的一个变种,alpha 不是固定的,而是作为一个参数通过网络训练学习得到。
5. ELU (Exponential Linear Unit, 指数线性单元)
公式: \[f(x) = \begin{cases} x & \text{if } x > 0 \\ \alpha(e^x - 1) & \text{if } x \le 0 \end{cases}\]
融合了 ReLU 和 Leaky ReLU 的优点。它在负区间有输出(避免神经元死亡),且输出均值接近于 0(类似 Tanh),有助于加速学习。在负区间的“软饱和”特性使其对噪声有一定的鲁棒性。
缺点是计算上比 ReLU 复杂(涉及指数运算)。
6. Softmax 函数
公式: \[f(x_i) = \frac{e^{x_i}}{\sum_{j} e^{x_j}}\]
严格来说,它更像是一个“归一化”函数,而非隐藏层的激活函数。它 专门用于多分类问题的输出层 。
它能将一个包含任意实数的向量,转换成一个“概率分布”向量。向量中所有元素的和为 1,且每个元素都在 0 和 1 之间,可以被解释为该样本属于各个类别的概率。
Softmax 没有一个统一的函数图,通常以概率分布柱状图来表示其输出结果。
7. Maxout 函数
Maxout 可以作为神经网络的隐藏层的激活函数。
隐藏层位于输入层和输出层之间。之所以被称为“隐藏”,是因为它的输入和输出既不是直接来自外部世界,也不是直接输出到外部世界,而是网络内部进行信息处理和转换的地方。一个神经网络可以有零个(例如简单的线性模型)或多个隐藏层。拥有多个隐藏层的网络称为深度神经网络(Deep Neural Network)。
Maxout 不是一个固定的非线性函数(如 ReLU 或 Sigmoid ),而是一个 可学习 的激活函数。它将输入分成若干组,然后输出每组中的最大值。 \[h(\mathbf{x}) = \max_{j \in [1, k]} (\mathbf{w}_{j}^T \mathbf{x} + b_j)\]
其中 x 是输入,w_j 和 b_j 是可学习的参数, k 是组的大小(通常称为 piece 或 unit 的数量)。
Maxout 具有 分段线性 的特性,并且可以 近似任何凸函数 是由多条直线段组成的折线图,形状上是一个凸函数。它在一定程度上避免了 ReLU 的“神经元死亡”问题,但在计算上和参数数量上会更复杂。
如何选择激活函数?
在现代深度学习实践中(特别是作为 Android 开发者,你可能接触到的 TFLite 模型中):
- 首选 ReLU:在绝大多数情况下,ReLU 是隐藏层的默认和首选。它简单、高效,并且效果很好。
- 尝试 ReLU 变体:如果发现 ReLU 导致了大量的“神经元死亡”,可以尝试使用 Leaky ReLU、PReLU 或 ELU 作为替代。
- 用于输出层:
- 二元分类(是/否):使用 Sigmoid。
- 多元分类(猫/狗/鸟):使用 Softmax。
- 回归任务(预测一个连续值,如房价):不使用激活函数(即线性输出)。
- Tanh 和 Sigmoid 现在较少用于深度网络的隐藏层,但在某些特定架构(如循环神经网络 RNN)中仍会见到 Tanh。