【AI】端侧模型部署llama.cpp篇

本文介绍了借助llama.cpp开源框架运行Android平台上的AI小模型的流程
接上文:
llama.cpp
作为一名 Android 开发者,llama.cpp 打开了在移动应用中实现端侧 AI 的全新大门。
llama.cpp 是一个由 Georgi Gerganov 开发的开源项目,其核心是用 C/C++ 编写的。它的主要目标是让大型语言模型 (LLMs) 能够在各种硬件上高效地运行推理,尤其是在本地设备上,包括那些没有高端独立 GPU 的普通电脑或移动设备。该项目的愿景是 “民主化”LLMs 的部署 ,让每个人都能在自己的设备上体验和使用这些强大的模型,而不仅仅依赖于昂贵的云服务。
对于Android平台,我们可以通过 Android NDK 将 llama.cpp 的 C/C++ 代码编译为 .so 库,并在您的 Java/Kotlin 代码中通过 JNI 调用它。llama.cpp 让您可以在 Android 应用中直接拥有一个“本地的智能大脑”,从而创造出前所未有的智能应用体验。
llama.cpp 的设计理念是追求极致的效率、最小化外部依赖、广泛的硬件兼容性以及高度的灵活性。

llama.cpp 并非一个虚拟机,而是一个高效的、C/C++ 实现的 LLM 推理引擎。它通过模型量化、GGUF 格式、底层硬件优化、多平台支持以及灵活的 API 接口,极大地降低了在个人电脑和边缘设备上运行大型语言模型的门槛。
模型量化
之前已经总结过,权重等参数是如何存储于大模型中的:
量化 是一种技术,可以将模型中通常以 32 位浮点数(FP32)或 16 位浮点数(FP16)存储的权重和激活值,转换为更低精度的格式,如 8 位整数(INT8)、4 位整数(INT4),甚至更低。降低了存储和传输模型的成本。使得更大的模型能够加载到有限的 RAM 或 VRAM 中。
模型的量化(Model Quantization)是一个在机器学习,尤其是深度学习领域中非常重要的概念,其核心目的是让模型变得更小、更快、更节能。
简单来说,模型的量化就是降低模型中数据的精度。
一个 FP32 的数字需要 4 字节(32位)。一个有数十亿参数的模型需要巨大的内存,计算开销相当高,浮点数计算比整数计算更耗时、耗电。
量化是如何工作的?
量化 就是将这些高精度的浮点数,转换成低精度的整数或更小的浮点数,比如:
- 8 位整数 (INT8)
- 4 位整数 (INT4 或 Q4_K)
- 16 位浮点数 (FP16 或 BF16)
假设你有一个模型的权重值是 0.785。在 FP32 中,它需要 4 个字节来存储。通过量化,它可以被映射到一个 8 位整数,比如 200,同时有一个缩放因子(Scale)和零点(Zero Point)来帮助在推理时近似还原原来的浮点数。
量化带来的好处
| 优势 | 描述 |
|---|---|
| 模型尺寸减小 | 将 FP32(4 字节)量化到 INT4(0.5 字节),理论上模型大小可以缩小8倍。这使得模型可以部署到内存有限的设备上。 |
| 推理速度加快 | 低精度的数据在特定的硬件(如 CPU、移动端 NPU)上可以更快地计算,因为它减少了内存访问,并允许使用更高效的整数运算单元。 |
| 能耗降低 | 更少的计算和更小的内存访问量,意味着模型在运行时消耗的电量更少,这对于移动设备和边缘计算非常重要。 |
量化类型分为两种:
- 训练后量化 (Post-Training Quantization, PTQ),这是最常见的量化方式。模型在 训练完成后 ,才进行量化转换。这种方式不需要重新训练模型,实现简单,成本低。对精度损失不太敏感,或希望快速部署模型的场景。
- 量化感知训练 (Quantization-Aware Training, QAT),这是在 训练过程中 就模拟量化后的低精度运算。由于模型在训练时就“知道”自己会被量化,因此可以更好地调整参数以 最小化精度损失 ,通常能获得比 PTQ 更好的性能。适合对精度要求较高,且愿意投入额外训练时间的场景。
在移动设备(如 Android 手机)上部署深度学习模型时, INT8量化 是常用的优化手段,因为移动设备的内存和计算资源都相对有限。
llama.cpp 框架特点
轻量与高效的 C/C++ 实现
llama.cpp 完全使用 C 和 C++ 编写,不依赖于大型的深度学习框架(如 TensorFlow 或 PyTorch)的运行时库。这意味着它编译出来的程序 体积非常小,运行时内存占用也低 。这对于资源受限的移动设备来说至关重要。
除了底层的 BLAS (基本线性代数子程序库) 或特定硬件的计算库(如 CUDA、Metal), llama.cpp 几乎没有其他复杂的外部依赖。这使得它非常容易编译和部署。
llama.cpp 对 CPU 进行了大量底层优化,利用了各种 CPU 指令集(如 x86-64 上的 AVX/AVX2/AVX-512,以及 ARM 上的 Neon)。这让 LLMs 可以在没有独立 GPU 的设备上,仅仅依靠 CPU 也能获得令人惊讶的推理速度。
广泛的硬件加速支持
除了强大的 CPU 优化,llama.cpp 还支持多种 GPU 和专用硬件加速,这意味着它是跨平台的,跨平台支持在任何行业都备受推崇,无论是游戏、人工智能还是其他类型的软件。赋予开发者在他们想要的系统和环境中运行软件所需的自由永远不是一件坏事。
- Apple Silicon (Metal):针对苹果 M 系列芯片的 Metal API 进行了优化,充分利用了其强大的统一内存架构和神经网络引擎。
- NVIDIA GPU (CUDA):支持 NVIDIA 显卡,通过 CUDA 加速推理,性能非常出色。
- AMD GPU (hipBLAS):兼容 AMD GPU。
- Intel GPU (SYCL/oneAPI):支持英特尔的集成和独立显卡。
- 通用 GPU 后端 (Vulkan/OpenCL):这对于 Android 开发者尤为重要。通过 OpenCL 后端,llama.cpp 能够利用 Android 设备中 SoC(System on Chip)内置的 GPU 或 DSP(数字信号处理器,如高通骁龙的 Hexagon DSP)进行加速,将推理负载从 CPU 转移到更擅长并行计算的硬件上。
- CPU + GPU 混合推理:对于一些较大的模型,即使单张 GPU 的显存不足以容纳整个模型,llama.cpp 也能将模型的某些层加载到 GPU 上运行,其余部分则在 CPU 上运行,实现资源的有效利用。
GGUF 文件格式
GGML
GGML 是一种为机器学习设计的文件格式和张量库,它最初由开发者 Georgi Gerganov 创建(GGML = Gerganov’s General Machine Learning)。它的核心目标是高效地在 CPU 上运行大型机器学习模型,特别是大型语言模型(LLMs),并且支持各种硬件平台。
GGML 的出现,是将 LLMs 带到消费级硬件上的关键一步。在它之前,运行大型模型通常需要昂贵的 GPU 和复杂的配置。GGML 通过一系列创新技术,让这些模型能够在普通的个人电脑上也能跑起来。
GGML 的核心是用 C 语言编写的,这意味着它的 执行效率非常高 ,并且依赖性极少。这使得它非常轻量级,可以在各种不同的操作系统和硬件上轻松编译和运行,包括 macOS、Linux、Windows,甚至 iOS 和 Android。
GGML 最初的重点在于在 CPU 上实现高效推理。它利用了现代 CPU 的特性,例如 SIMD(单指令多数据)指令集 ,比如 Intel 的 AVX、AVX2、AVX512 和 ARM 的 NEON,这些指令允许 CPU 同时处理多个数据点,从而加速矩阵乘法等并行计算。可以利用 CPU 的多个核心并行执行计算任务。
GGUF格式的出现
GGUF (GPT-Generated Unified Format) 就是 GGML 文件格式的最新演进版本。GGUF 在 GGML 的基础上,提供了更强的灵活性、更好的向后兼容性,并能包含更多的元数据(例如分词器信息、提示模板等),使其成为目前社区首选的本地 LLM 格式。
可以把它想象成一个 包含了模型“大脑”里所有知识的“盒子” ,这个盒子设计得非常紧凑和高效,便于在各种设备上快速打开和使用。
GGUF 格式支持从全精度 (FP32) 到半精度 (FP16) 以及多种低精度(如 INT8、INT5、INT4、INT2)的模型量化。量化可以在牺牲极小精度损失的情况下,大幅减小模型体积,降低内存占用和计算需求。这对于在手机上运行大型模型至关重要,能让原本无法加载的模型变得可用。
GGUF 文件不仅包含模型权重,还打包了模型的词表、超参数、架构信息和特殊 token ID 等所有运行所需的元数据。一个 GGUF 文件就是一个独立的、可运行的模型包。
此外,GGUF 支持内存映射。这意味着操作系统可以直接将文件内容映射到内存中,而无需将整个模型完全复制到 RAM。这大大加快了模型加载速度,并允许在物理内存不足的情况下也能运行大模型(通过操作系统的虚拟内存管理)。
模型文件命名约定
GGUF 遵循命名约定, <BaseName><SizeLabel><FineTune><Version><Encoding><Type><Shard>.gguf 每个组件之间用 - 分隔。这样做的最终目的是让人们能够一目了然地了解模型的最重要细节。
这些组件包括:
- BaseName:模型基础类型或架构的描述性名称。
- SizeLabel:参数权重类(对排行榜有用)表示为
<expertCount>x<count><scale-prefix> - FineTune:模型微调目标的描述性名称(例如聊天、指导等…)
- 版本:(可选)表示模型版本号,格式为
v<Major>.<Minor> - 编码:表示应用于模型的权重编码方案。内容、类型组合和排列由用户代码决定,并可能根据项目需求而变化。
- 类型:表示 gguf 文件的类型及其预期用途
- Shard:(可选)表示并表明模型已被拆分为多个分片,格式为
<ShardNum>-of-<ShardTotal>。
例如:Mixtral-8x7B-v0.1-KQ2.gguf:
型号名称:Mixtral
专家数量:8
参数数量:7B
版本号:v0.1
权重编码方案:KQ2
GGUF 文件的结构
一个 GGUF 文件大致可以分为两个主要部分:
- 头部 (Header):包含 GGUF 文件的魔数(用于识别文件类型)、版本号以及一些全局元数据(如模型总层数、维度等)。
- 元数据 (Metadata) 和张量 (Tensors):
- KV 对 (Key-Value Pairs):存储了模型的各种超参数、架构信息、词表和一些其他配置。这些都是以键值对的形式存储的,方便访问。
- 张量数据 (Tensor Data):这是模型真正的权重数据。每个张量都会有其名称、维度和数据类型(例如,量化后的 INT4、INT8 或 FP16 等)。这些数据会按照特定的对齐方式存储,以确保高效读取。

运行原理简介
详细运行流程见原文:
【AI】Understanding how LLM inference works with llama.cpp
即使没有高性能的独立 GPU 的设备也可以运行大模型,但这通常会有一些重要的限制和权衡。
CPU 也能执行并行计算 ,现代 CPU 通常有多个核心,并且支持 SIMD (Single Instruction, Multiple Data) 指令集(如 Intel 的 AVX、SSE 指令集),这使得它们能够同时处理少量数据。例如机器学习框架(如 TensorFlow 或 PyTorch),在设备没有GPU时,会自动回退到使用 CPU 来执行所有的矩阵乘法和其他计算。这些框架的 CPU 版本也会进行高度优化,以尽可能利用 CPU 的并行能力。
传统的 CPU 指令(称为 标量指令 或 SISD - Single Instruction, Single Data)一次只能对一个数据对(例如,两个整数或浮点数)进行操作。相比之下,SIMD 指令将多个数据项打包到一个特殊的 宽寄存器 中,然后一次性对所有这些数据项执行相同的操作。向量寄存器是 SIMD 的关键。它们比普通的通用寄存器宽得多。常见的宽度有 128位、256位,以及最新的 512位。假设有一个 256 位的寄存器和 32 位的整数。您可以将 256/32=8 个整数打包到这个寄存器中。当 CPU 执行一个 SIMD 加法指令时,它会在一个时钟周期内同时对这 8 个整数执行加法操作。这就像将一条生产线变成了八条。
相比于大模型的训练,推理阶段的计算量相对较小 ,训练大模型需要极其强大的 GPU,因为它涉及数万亿次的参数更新,需要多次迭代和反向传播。而在 推理(Inference) 阶段,即模型用于实际预测时,只需要进行前向传播。虽然计算量依然庞大,但比训练时少得多。对于量化后的模型,推理的计算需求会进一步降低。
本质上,llama.cpp 加载数据,构建计算图并进行计算。主要关注点也是在于使用高效的 SIMD 指令在 CPU 上运行——这内置于库的核心实现中(ggml.c)。后端(ggml-cuda、ggml-metal等)用于在 GPU 加速器上计算图。
因此,它是一个通用 API,可以更轻松地在项目中运行 gguf 模型。如果有非常具体的需求或用例,也可以直接在其基础上构建 gguf,或者通过删除不必要的内容来创建一个精简版本 llama.cpp。
它使用 llama_init_from_file 函数从 gguf 文件初始化一个 llama 上下文。此函数读取 gguf 文件的头文件和正文,并创建一个 llama 上下文对象,该对象包含模型信息和运行模型的后端(CPU、GPU 或 Metal)。
再使用 llama_tokenize 函数对输入文本进行标记。此函数根据 gguf 文件头中指定的标记器将输入文本转换为标记序列。这些标记存储在一个 llama 标记数组中, llama 标记是表示标记 ID 的整数。
在执行推理生成时,通过 llama_generate 函数生成输出文本。此函数将输入标记和 llama 上下文作为参数,并在后端运行模型。它使用 gguf 文件头中指定的计算图执行模型的前向传递并计算下一个标记的概率。然后,它从概率分布中采样下一个标记并将其附加到输出标记中。它会重复此过程,直到文本结束标记或达到最大标记数。输出标记存储在另一个 llama 标记数组中。
最后通过 llama_detokenize 函数对输出文本进行去标记化。该函数根据 gguf 文件头中指定的标记器将输出标记转换为文本字符串。它会处理特殊标记,例如文本结束标记、填充标记和未知标记,并返回最终的输出文本。
部署运行实操
接下来介绍下如何在项目中集成llama.cpp,从而加载gguf格式的模型,运行本地的小模型。
一、使用Termux命令行编译运行
这种方法就是将 Android 设备当作 Linux 设备来使用,手机需要安装Termux。
可以在Github Releases 选择 termux-app_v0.118.2+github-debug_arm64-v8a.apk 下载,并且安装到手机。
下载 llama.cpp 库:
# 切换国内源
termux-change-repo
apt list --upgradable
# 安装依赖工具
pkg install -y cmake git build-essential
# 下载 llama.cpp
git clone https://github.com/ggml-org/llama.cpp.git
# 如果git下不下来,通过scp拷贝进去
scp -P 8022 .\llama.cpp-master.zip u0_a456@192.168.31.44:~
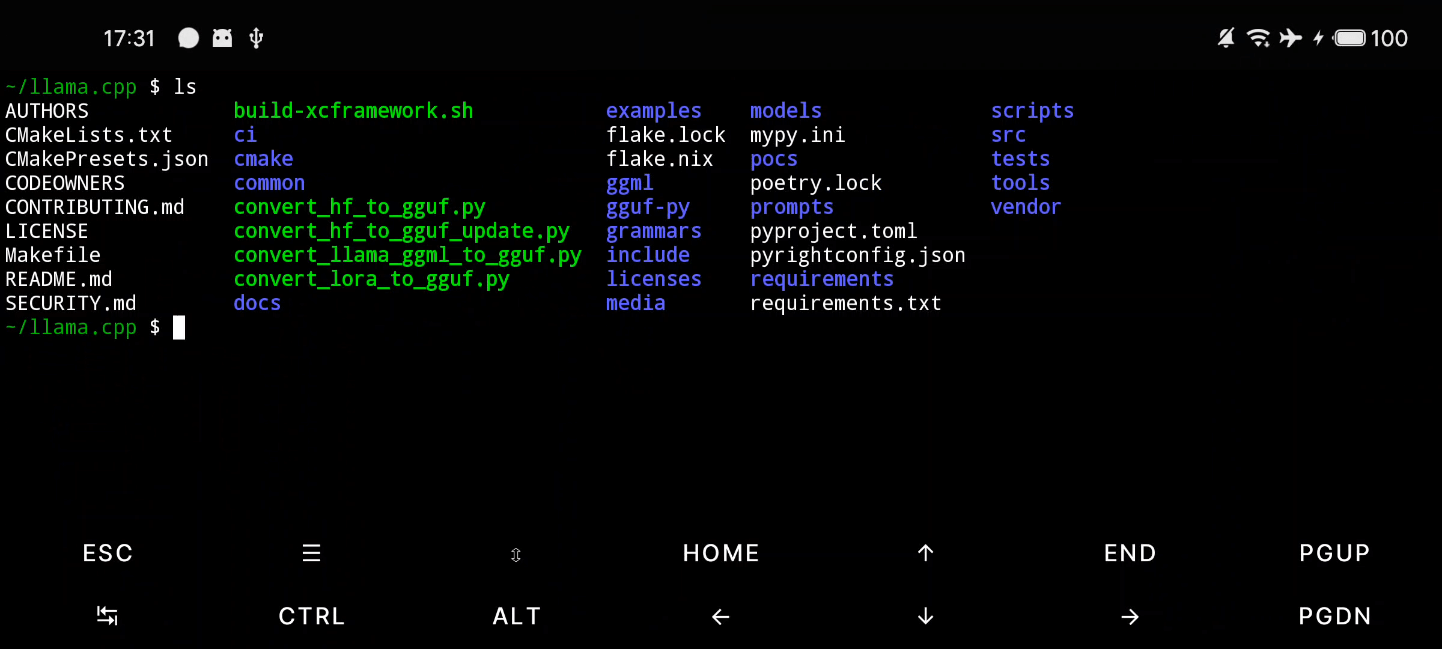
编译llama.cpp源代码:
# 进入目录
cd llama.cpp
# 创建build文件,并且进入文件夹
mkdir build && cd build
# 生成编译配置,-DGGML_CUDA=OFF 关闭GPU
cmake .. -DGGML_CUDA=OFF
# 4个线程编译
make -j4
# 编译完成目录在/bin
ls ~/llama.cpp/build/bin
# bin添加到环境变量中
echo 'export PATH=$PATH:~/llama.cpp/build/bin/' >> ~/.bashrc
source ~/.bashrc
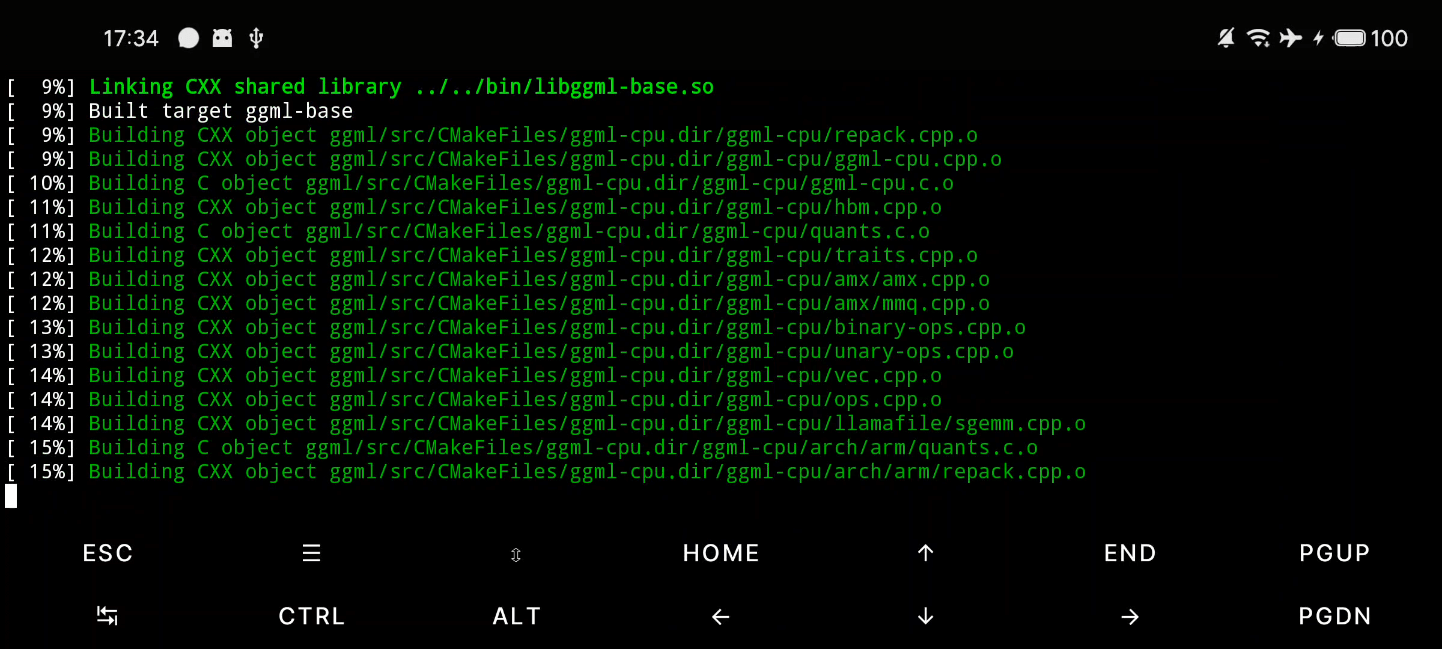
直接从 Hugging Face 下载 .gguf 文件,避免转换步骤。我下载的是 DeepSeek-R1-Distill-Qwen-1.5B-Q2_K.gguf 。网络问题,推荐在电脑端下载完毕,通过USB使用adb或者文件模式,推送到手机端。
注意Termux默认是无法操作手机文件系统的,需要执行命令来获取权限,初始化文件管理系统。
termux-setup-storage
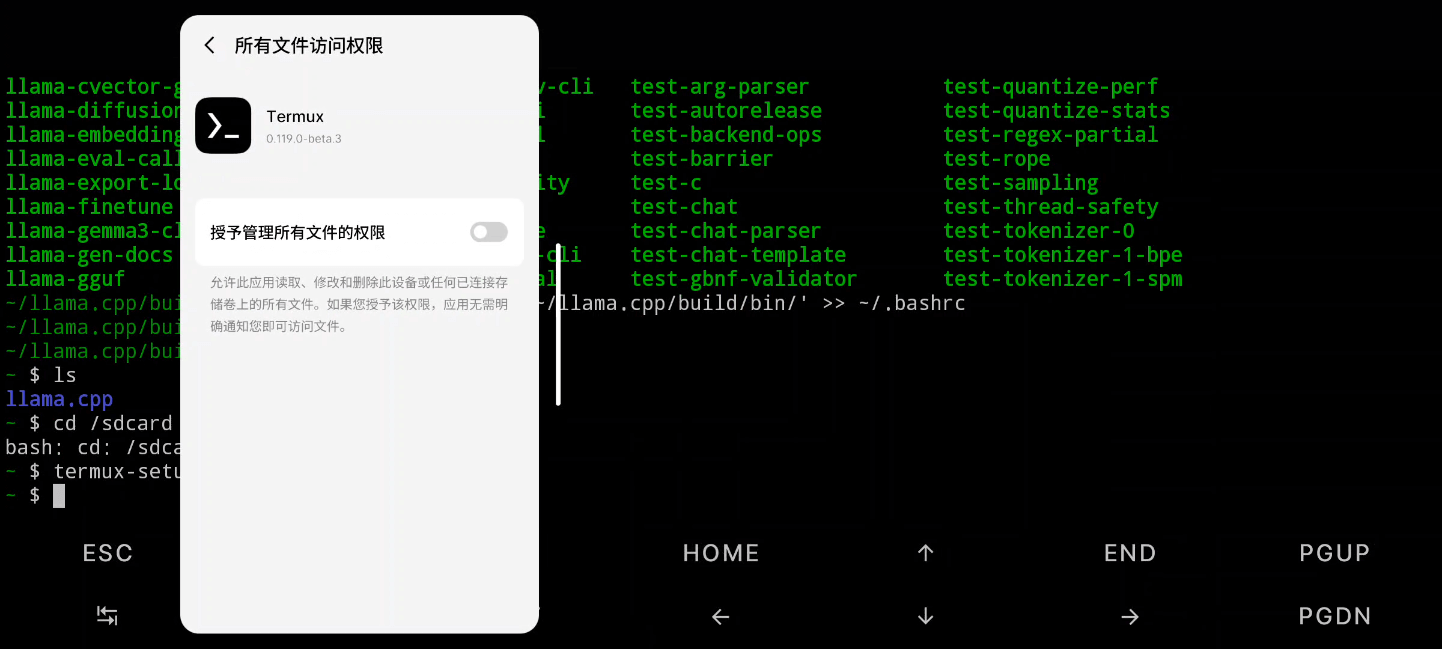
出现管理所有文件的权限授予弹窗,打开之后将文件复制到内部目录:
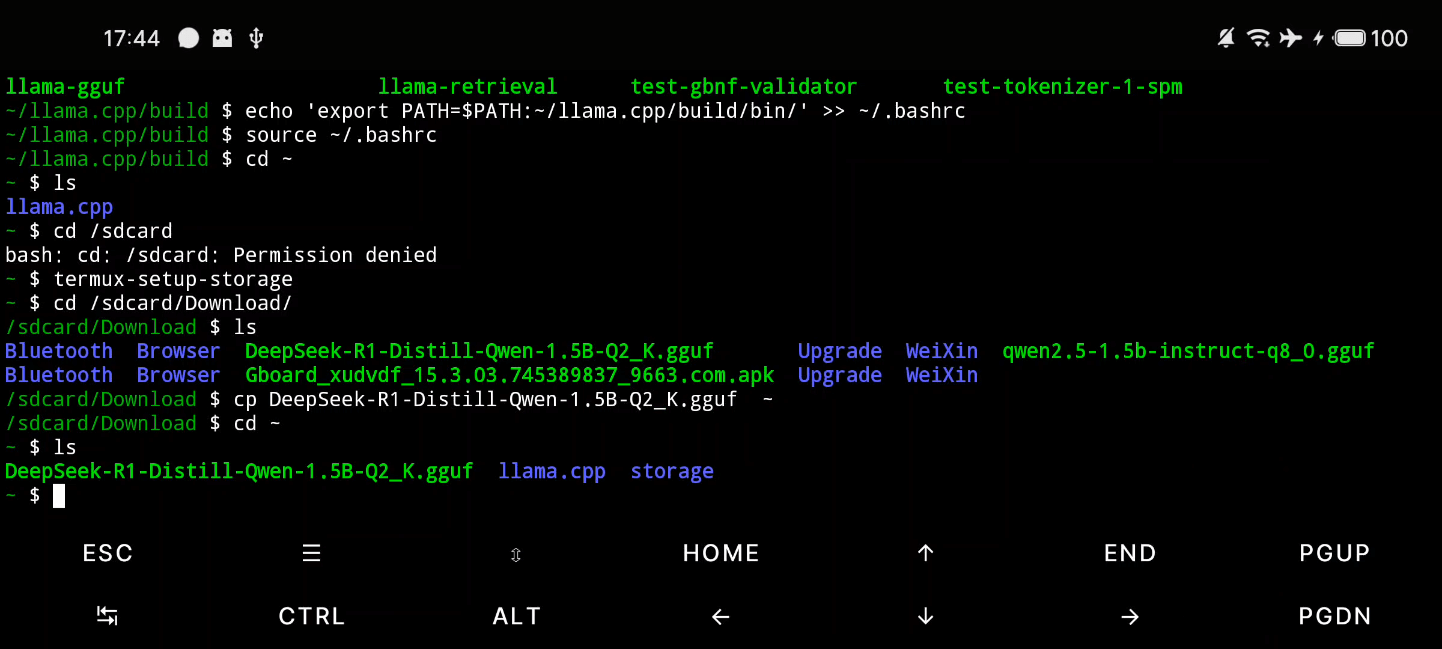
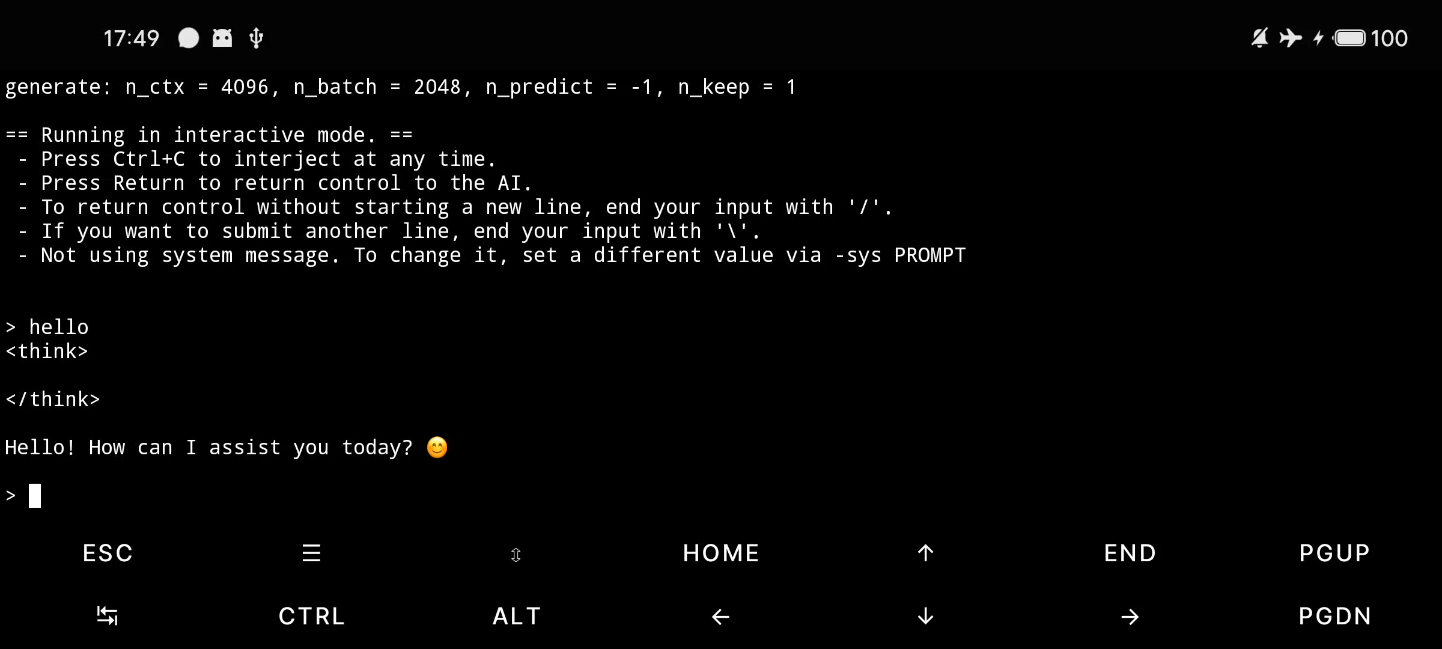
可以先试试运行效果,使用 llama-cli 直接在命令行中启动:
llama-cli -m DeepSeek-R1-Distill-Qwen-1.5B-Q2_K.gguf
llama-cli,即 CLI 模式(Command-Line Interface 模式)是指通过命令行直接运行模型进行推理(文本生成)的方式,而不是通过 API 或图形界面。这是 llama.cpp 最基础的使用方式,适合本地测试、脚本调用或服务器部署。
运行效果如下:
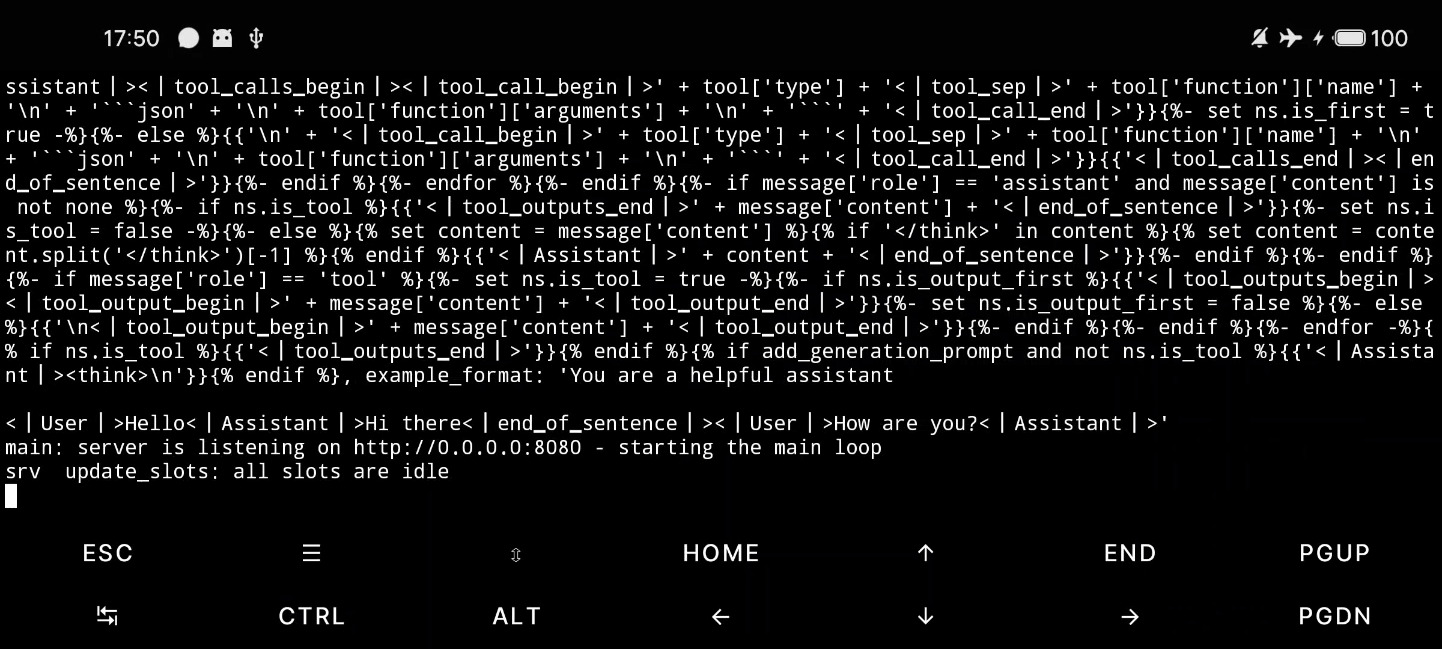
也可以使用 llama-server 的方式启动:
llama-server -m DeepSeek-R1-Distill-Qwen-1.5B-Q2_K.gguf --port 8080 --host 0.0.0.0
手机端client直接访问
通过 llama-server 作为服务器启动之后,我们可以直接在手机端编写client,通过http请求来访问,直接和这个服务交互。这里大部分可以复用之前写的和deepseek官方api的请求逻辑。
网络Repository代码:
class DeepseekChatRepository(private val ktorClient: KtorClient) {
companion object {
const val BASE_URL =
"https://api.deepseek.com"
const val LOCAL_SERVER = "http://0.0.0.0:8080/v1"
const val COMMON_SYSTEM_PROMT = "你是一个人工智能系统,可以根据用户的输入来返回生成式的回复"
const val ENGLISH_SYSTEM_PROMT =
"You are a English teacher, you can help me improve my English skills, please answer my questions in English."
const val API_KEY = "xxxxxxxxxxxxxxxxx"
const val MODEL_NAME = "deepseek-chat"
}
suspend fun localLLMChat(chat: String) = withContext(Dispatchers.IO) {
ktorClient.client.post("${LOCAL_SERVER}/chat/completions") {
// 配置请求头
headers {
append("Content-Type", "application/json")
}
setBody(
DeepSeekRequestBean(
model = "DeepSeek-R1-Distill-Qwen-1.5B-Q2_K",
max_tokens = 256,
temperature = 0.7f,
stream = false,
messages = listOf(
RequestMessage(COMMON_SYSTEM_PROMT, ChatRole.SYSTEM.roleDescription),
RequestMessage(chat, ChatRole.USER.roleDescription)
)
)
)
}.body<LocalModelResult>()
}
}
界面上维护一个chatListState,里面是一个
data class AiChatUiState(
val chatList: List<ChatItem> = listOf(),
val listSize: Int = chatList.size
) {
fun toUiState() = AiChatUiState(chatList = chatList, listSize = listSize)
}
data class ChatItem(
val content: String,
val role: ChatRole,
)
界面观察这个State响应式刷新即可。
运行结果:
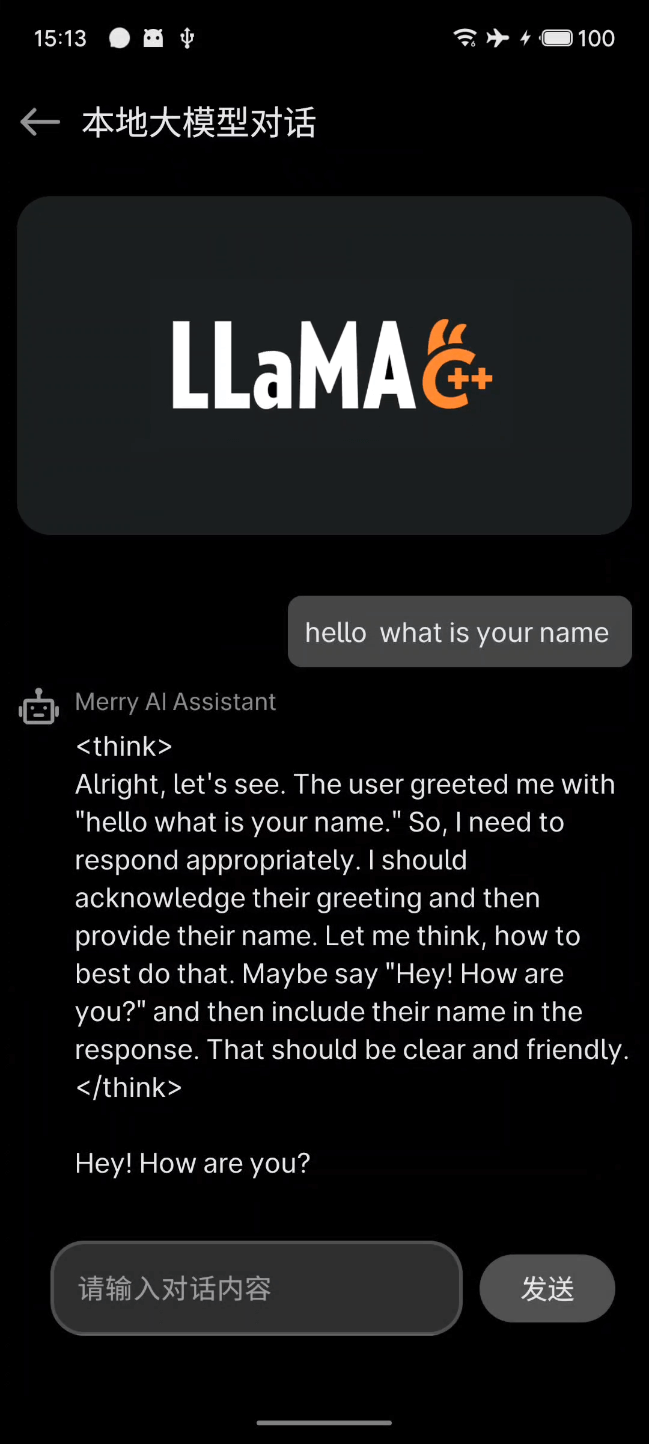
局域网内其他设备访问
除了同一设备直接访问本地服务,在同一个局域网中,比如电脑端,我们也可以使用Python,通过 openai 的Python开发套件,和手机端运行的服务进行通信:
import requests
import json
import time
API_URL = "http://192.168.31.44:8080/v1/chat/completions"
payload = {
"model": "DeepSeek-R1-Distill-Qwen-1.5B-Q2_K", # llama-server 中可随意写
"messages": [
{"role": "system", "content": "你是一个英语学习助手。"},
{"role": "user", "content": "请用中文解释单词 ability 的含义,并给出一个英文例句。"}
],
"temperature": 0.7,
"max_tokens": 256,
"stream": False
}
# 记录开始时间
start_time = time.time()
# 发送请求
response = requests.post(API_URL, headers={"Content-Type": "application/json"}, data=json.dumps(payload))
# 记录结束时间
end_time = time.time()
if response.ok:
result = response.json()
message = result['choices'][0]['message']['content']
print("模型回复:\n", message)
# 处理 token usage 和速度统计
usage = result.get("usage", {})
total_tokens = usage.get("total_tokens", "未知")
elapsed = end_time - start_time
print(f"\n总 tokens: {total_tokens}")
print(f"耗时: {elapsed:.2f} 秒")
if isinstance(total_tokens, int) and elapsed > 0:
print(f"生成速度: {total_tokens / elapsed:.2f} tokens/秒")
else:
print("请求失败,状态码:", response.status_code)
print(response.text)
二、单进程集成方案
上面那种在Termux中运行模型的方式还是感觉比较麻烦,每次也需要手动开启服务。
下面这种方案就是比较符合 Android 设备上运行的直观预期,通过一个APP页面来承载功能,在一个应用中,以用户友好的 UX交互 来和本地模型进行通信。使用JNI开发接口和llama.cpp交互。
底层依然是使用 llama.cpp 加载和执行 GGUF 模型。由于 llama.cpp 是用纯 C/C++ 编写的,因此很容易在apk编译阶段利用 AndroidStudio 的NDK工具,打包为 .so 动态库,在端侧运行。
GGUF文件读取
首先,定义JNI函数,第一步需要加载 gguf 文件。在 Android 应用中,需要使用 Kotlin 语言来定义页面需要用到的接口,再到 Native 层使用 llama.cpp 的能力,来编写 C++ 的桥接代码。
class GGUFReader {
companion object {
init {
System.loadLibrary("ggufreader")
}
}
private var nativeHandle: Long = 0L
suspend fun load(modelPath: String) =
withContext(Dispatchers.IO) {
nativeHandle = getGGUFContextNativeHandle(modelPath)
}
fun getContextSize(): Long? {
assert(nativeHandle != 0L) { "Use GGUFReader.load() to initialize the reader" }
val contextSize = getContextSize(nativeHandle)
return if (contextSize == -1L) {
null
} else {
contextSize
}
}
fun getChatTemplate(): String? {
assert(nativeHandle != 0L) { "Use GGUFReader.load() to initialize the reader" }
val chatTemplate = getChatTemplate(nativeHandle)
return chatTemplate.ifEmpty {
null
}
}
private external fun getGGUFContextNativeHandle(modelPath: String): Long
private external fun getContextSize(nativeHandle: Long): Long
private external fun getChatTemplate(nativeHandle: Long): String
}
nativeHandle 是一个长整型(Long)变量,代表指向本地(C/C++)端创建的 gguf_context 的指针。在 Native 代码里,gguf_context 是一个上下文对象,负责管理 GGUF 文件的读取操作。nativeHandle 唯一标识这个上下文对象,方便 Kotlin 代码引用。借助 nativeHandle 能把本地对象的地址传递给 Kotlin 代码,进而在 Kotlin 代码里调用本地函数操作这些对象。
定义的三个JNI方法作用分别如下:
getGGUFContextNativeHandle(): 加载模型文件,返回模型上下文的指针。getContextSize(): 获取模型上下文的大小,即模型参数的数量。getChatTemplate(): 获取模型的聊天模板,用于生成聊天对话的提示。
在Native层的代码中,实现也非常简单,引入 llama.cpp 中的 gguf.h 头文件。
在获取上下文指针的方法中,传入模型文件的绝对地址字符串,调用 gguf_init_from_file ,即可获取到 gguf_context 对象指针,转换回 jlong 类型传递给Kotlin即可。
第二,在获取模型参数数量的方法中,需要先从 gguf_context 中找到 architecture 字段,再根据 architecture 字段的值,拼接出 context_length 字段的名称,最后调用 gguf_get_val_u32 方法获取参数数量。
第三个方法是获取模型的聊天模板,需要先找到分词器 tokenizer.chat_template 字段,调用 gguf_get_val_str 方法获取字符串值。
#include "gguf.h"
#include <jni.h>
#include <string>
extern "C" JNIEXPORT jlong JNICALL
Java_com_stephen_llamacppbridge_GgufFileReader_getGGUFContextNativeHandle(JNIEnv *env, jobject thiz,
jstring modelPath) {
jboolean isCopy = true;
const char *modelPathCStr = env->GetStringUTFChars(modelPath, &isCopy);
// 初始化 GGUF 上下文所需的参数,不分配额外内存,上下文指针初始化为 nullptr
gguf_init_params initParams = {.no_alloc = true, .ctx = nullptr};
// 根据模型文件路径和初始化参数创建 GGUF 上下文
gguf_context *ggufContext = gguf_init_from_file(modelPathCStr, initParams);
env->ReleaseStringUTFChars(modelPath, modelPathCStr);
return reinterpret_cast<jlong>(ggufContext);
}
extern "C" JNIEXPORT jlong JNICALL
Java_com_stephen_llamacppbridge_GgufFileReader_getContextSize(JNIEnv *env, jobject thiz,
jlong nativeHandle) {
gguf_context *ggufContext = reinterpret_cast<gguf_context *>(nativeHandle);
// 查找模型架构信息对应的键 ID
int64_t architectureKeyId = gguf_find_key(ggufContext, "general.architecture");
// 若未找到架构信息键 ID,返回 -1
if (architectureKeyId == -1)
return -1;
// 获取模型架构信息
std::string architecture = gguf_get_val_str(ggufContext, architectureKeyId);
// 构建上下文长度信息对应的键名
std::string contextLengthKey = architecture + ".context_length";
// 查找上下文长度信息对应的键 ID
int64_t contextLengthKeyId = gguf_find_key(ggufContext, contextLengthKey.c_str());
// 若未找到上下文长度信息键 ID,返回 -1
if (contextLengthKeyId == -1)
return -1;
uint32_t contextLength = gguf_get_val_u32(ggufContext, contextLengthKeyId);
return contextLength;
}
extern "C" JNIEXPORT jstring JNICALL
Java_com_stephen_llamacppbridge_GgufFileReader_getChatTemplate(JNIEnv *env, jobject thiz,
jlong nativeHandle) {
gguf_context *ggufContext = reinterpret_cast<gguf_context *>(nativeHandle);
// 查找聊天模板信息对应的键 ID
int64_t chatTemplateKeyId = gguf_find_key(ggufContext, "tokenizer.chat_template");
// 存储聊天模板的字符串
std::string chatTemplate;
// 若未找到聊天模板信息键 ID,将聊天模板设为空字符串
if (chatTemplateKeyId == -1) {
chatTemplate = "";
} else {
// 若找到聊天模板信息键 ID,获取聊天模板信息
chatTemplate = gguf_get_val_str(ggufContext, chatTemplateKeyId);
}
return env->NewStringUTF(chatTemplate.c_str());
}
模型的加载与对话
gguf 文件成功读取和加载后,就可以运行LLM的推理功能了。
根据 llama.cpp 的几个核心的方法,如加载,对话等功能,来编写对接的接口 C++ 类。
关于第一步加载模型 load_1model ,官方例程的JNI接口编写如下:
extern "C"
JNIEXPORT jlong JNICALL
Java_android_llama_cpp_LLamaAndroid_load_1model(JNIEnv *env, jobject, jstring filename) {
// 获取模型的默认参数
llama_model_params model_params = llama_model_default_params();
// 将 Java String 转换为 C 风格字符串
auto path_to_model = env->GetStringUTFChars(filename, 0);
LOGi("Loading model from %s", path_to_model);
// 调用 llama.cpp 核心函数加载模型
auto model = llama_model_load_from_file(path_to_model, model_params);
// 释放 C 风格字符串,防止内存泄漏
env->ReleaseStringUTFChars(filename, path_to_model);
if (!model) {
LOGe("load_model() failed");
// 如果加载失败,抛出 Java 异常
env->ThrowNew(env->FindClass("java/lang/IllegalStateException"), "load_model() failed");
return 0;
}
// 将 C++ 指针转换为 jlong 返回给 Java
return reinterpret_cast<jlong>(model);
}
返回的是一个指向结构体 llama_model 的指针,这是 llama.cpp 库中最核心的结构体之一,它代表了加载到内存中的整个大语言模型 (LLM)。
这个 llama_model 结构体中包含了 模型的元数据、超参数、词汇表、所有权重张量以及硬件配置信息 。
struct llama_model {
// 模型的类型(例如 LLaMA, Falcon, Mixtral 等)
llm_type type = LLM_TYPE_UNKNOWN;
// 模型的架构(llm_arch 是 llama.cpp 内部用于区分不同模型结构的枚举)
llm_arch arch = LLM_ARCH_UNKNOWN;
// 模型的名称或描述
std::string name = "n/a";
// 模型超参数:包含模型的固定配置,如层数、注意力头数、KV 缓存上下文长度等
llama_hparams hparams = {};
// 模型的词汇表(Vocabulary):包含 Token 列表及其与 ID 的映射关系
llama_vocab vocab;
// 用于分类器模型(如 Sentiments Analysis)的标签列表
std::vector<std::string> classifier_labels;
// ggml_tensor* 是 ggml 库中的张量指针,存储模型的权重数据。
// 这部分包含了不同模型架构共有的或用于输入处理的权重。
// Token 嵌入层权重 (Token Embeddings)
struct ggml_tensor * tok_embd = nullptr;
// Token 类型嵌入层权重(例如用于 BERT 风格模型区分句子 A 和 B)
struct ggml_tensor * type_embd = nullptr;
// 位置嵌入层权重 (Positional Embeddings)
...
// -------------------------------------------------------------------------
// 3. 特殊张量 (Specialized Tensors)
// -------------------------------------------------------------------------
// **分类器张量 (Classifier Tensors)**
struct ggml_tensor * cls = nullptr; // 分类器权重
struct ggml_tensor * cls_b = nullptr; // 分类器偏置
struct ggml_tensor * cls_out = nullptr; // 分类器输出层权重
struct ggml_tensor * cls_out_b = nullptr; // 分类器输出层偏置
// **1D 卷积张量 (用于某些早期模型如 GPT-2 或特殊层)**
struct ggml_tensor * conv1d = nullptr;
struct ggml_tensor * conv1d_b = nullptr;
...
// 4. 配置与运行状态 (Configuration and Runtime State)
...
// 创建上下文内存结构体(KV 缓存等)
// note: can mutate `cparams`
// TODO: move this to new llm_arch_model_i interface
llama_memory_i * create_memory(const llama_memory_params & params, llama_cparams & cparams) const;
// 构建 ggml 计算图:将模型计算逻辑转化为可执行的计算图
// TODO: move this to new llm_arch_model_i interface
ggml_cgraph * build_graph(const llm_graph_params & params) const;
};
llama_model_load_from_file 函数最终调用到了 llama_model_load_from_file_impl 函数,看看这里面做了哪些工作:
/**
* @brief 核心实现函数:从文件加载 LLM 模型到 llama_model 结构体中。
* @param path_model 模型文件的主要路径。
* @param splits 如果模型被分割成多个文件,包含其余文件路径的向量。
* @param params 模型加载参数,如设备选择、KV 缓存大小等。
* @return 成功加载的 llama_model 指针,失败返回 nullptr。
*/
static struct llama_model * llama_model_load_from_file_impl(
const std::string & path_model,
std::vector<std::string> & splits,
struct llama_model_params params) {
// 初始化 ggml 库的计时器
ggml_time_init();
// 1. 后端检查 (Backend Check)
// 如果不是只加载词汇表,并且没有注册任何计算后端,则报错。
// 第二个条件是为了确保 llama.cpp 运行时环境中有可用的硬件(或软件)模块来执行模型的实际计算。
if (!params.vocab_only && ggml_backend_reg_count() == 0) {
LLAMA_LOG_ERROR("%s: no backends are loaded. hint: use ggml_backend_load() or ggml_backend_load_all() to load a backend before calling this function\n", __func__);
return nullptr;
}
// 2. 进度回调设置 略
// 在堆上创建 llama_model 实例,保存模型参数
llama_model * model = new llama_model(params);
// 3. 计算设备选择 (Device Selection)
// 这一段决定了模型中的权重和计算将在哪些设备上(如 GPU、集成 GPU 或远程服务器)运行,而不是完全依赖 CPU。根据用户参数和系统环境,构建一个最优的计算设备列表(model->devices),用于模型权重和计算的分配。
// 4. 单 GPU 模式调整 (Single GPU Mode Adjustment)
// 如果是单设备模式 (LLAMA_SPLIT_MODE_NONE),则只保留主设备
if (params.split_mode == LLAMA_SPLIT_MODE_NONE) {
if (params.main_gpu < 0) {
// main_gpu < 0 表示强制在 CPU 上运行
model->devices.clear();
} else {
// 检查指定的 main_gpu 索引是否有效
if (params.main_gpu >= (int)model->devices.size()) {
LLAMA_LOG_ERROR("%s: invalid value for main_gpu: %d (available devices: %zu)\n", __func__, params.main_gpu, model->devices.size());
llama_model_free(model);
return nullptr;
}
// 仅保留指定的主 GPU
ggml_backend_dev_t main_gpu = model->devices[params.main_gpu];
model->devices.clear();
model->devices.push_back(main_gpu);
}
}
// 5. 实际模型加载 (Actual Model Loading)
// 调用 llama.cpp 库的底层函数来执行实际的文件读取和权重加载
const int status = llama_model_load(path_model, splits, *model, params);
GGML_ASSERT(status <= 0); // 确认 status <= 0 (成功或取消/失败)
// 检查加载状态,如果加载失败,释放已分配的 llama_model 内存
// 并返回空指针
// llama_model_free(model);
// return nullptr;
// 6. 返回load的结果
return model;
}
可以看到, llama_model_load_from_file_impl 方法是确定运行的设备环境是否符合要求,除CPU之外,是否有GPU和远程设备可以使用。
实际的模型初始化加载函数为 llama_model_load ,其中有5个核心的加载步骤:
const int status = llama_model_load(path_model, splits, *model, params);
// void load_stats (llama_model_loader & ml);
// void load_arch (llama_model_loader & ml);
// void load_hparams(llama_model_loader & ml);
// void load_vocab (llama_model_loader & ml);
// bool load_tensors(llama_model_loader & ml);
如备注,其中会调用如下几个函数:
load_stats,读取模型的元数据和统计信息。包括模型的创建时间、上次修改时间、版本号等非关键但有用的信息。在 GGUF 格式中,这些信息通常存储在头部或元数据区。load_arch,负责识别和设置模型的核心架构信息。它读取模型文件中的架构类型(如 LLaMA、Gemma、Mixtral 等),并设置llama_model结构体中的arch和type字段,为后续的超参数和张量加载做准备。load_hparams,负责加载模型的超参数 (Hyperparameters)。这些参数定义了模型的结构和大小,包括:层数 (n_layer)、嵌入维度 (n_embd)、注意力头数 (n_head)、上下文窗口大小 (n_ctx) 等。这些参数是构建模型计算图和分配 KV 缓存所必需的。load_vocab, 负责加载模型的词汇表 (Vocabulary)。词汇表包含所有 Token 及其对应的 ID。这个步骤确保模型知道如何将输入的文本分词 (tokenize) 成数字 ID,以及如何将输出的数字 ID 转换回可读的文本。它填充了llama_model中的vocab结构体。load_tensors,最关键的步骤。负责将模型的所有权重张量(如tok_embd,wq,wk,wv,wo等)从磁盘读取到内存或分配给选定的硬件设备(GPU)。这个过程通常涉及大量的数据传输和内存分配。它返回一个布尔值,用于指示加载是否被用户的进度回调函数取消。
数据预处理:添加系统提示和用户提示
模型加载完毕之后,我们可以单独提前加入系统prompt提示语:
// 存储聊天过程中用户和助手的消息列表
std::vector<llama_chat_message> _messages;
后续用户的聊天消息也会被添加进这个数组里,一起作为推理输入。
当用户输入一个请求,会在 startCompletion 函数中对所有的数据进行预处理,这个函数完成了所有开始推理前的准备工作,为后续的推理调用铺平了道路。使用 llama_chat_apply_template 将用户消息 (query) 格式化为 LLM 模型能够理解的、带有特殊标记(如 [INST] , <<SYS>> )的完整 Prompt 字符串。调用 common_tokenize 将格式化后的 Prompt 字符串转换成模型需要的数字 ID 序列(_promptTokens)。创建并填充 llama_batch 结构体,将 Token ID 序列和数量赋值给它。
void
LLMInference::startCompletion(const char *query)
第一步会把最新的用户请求也添加进 _messages 数组中。
// 添加用户类型的prompt
addChatMessage(query, "user");
接着调用 llama_chat_apply_template 函数,将内部消息列表 (_messages) 格式化为模型可接受的 Prompt 字符串 (_formattedMessages)
int newLen = llama_chat_apply_template(_chatTemplate, // 聊天模板句柄
_messages.data(), // 输入消息列表
_messages.size(), // 消息数量
true, // 强制添加 BOS(开始标记)
_formattedMessages.data(), // 输出缓冲区
_formattedMessages.size());// 输出缓冲区大小
然后会对这个 prompt 进行分词和解码。
std::string prompt(_formattedMessages.begin() + _prevLen, _formattedMessages.begin() + newLen);
_promptTokens = common_tokenize(llama_model_get_vocab(_model), prompt, true, true);
// create a llama_batch containing a single sequence
// see llama_batch_init for more details
_batch = new llama_batch();
_batch->token = _promptTokens.data();
_batch->n_tokens = _promptTokens.size();
一个序列的所有 Prompt 会被打包进一个 llama_batch ,其中只有最后一个 Token 的 logits 字段会被设为 true,以预测下一个 Token。以批量(Batch)的方式将一个或多个序列的 Token 输入给模型准备进行一次前向计算。
推理的触发
数据准备好之后,就可以循环调用 completionLoop 函数来进行对话补全推理:
/**
* 循环获取 LLM 模型生成的响应片段。
*/
extern "C" JNIEXPORT jstring JNICALL
Java_com_stephen_llamacppbridge_LlamaCppBridge_completionLoop(JNIEnv* env, jobject thiz, jlong modelPtr) {
// 将 jlong 类型的指针转换为 LLMInference 实例指针
auto* llmInference = reinterpret_cast<LLMInference*>(modelPtr);
try {
// 调用 LLMInference 实例的 completionLoop 方法获取响应片段
std::string response = llmInference->completionLoop();
// 将 C++ 字符串转换为 Java 字符串并返回
return env->NewStringUTF(response.c_str());
} catch (std::runtime_error& error) {
// 若生成过程中抛出异常,在 Java 层抛出 IllegalStateException 异常
env->ThrowNew(env->FindClass("java/lang/IllegalStateException"), error.what());
return nullptr;
}
}
调用到 llama.cpp 框架的 completionLoop 函数,它负责在模型已经处理完初始 Prompt 之后,每调用一次就生成并处理下一个 Token 。
/**
* 执行一次模型推理,采样下一个 Token,并处理输出。
*/
std::string
LLMInference::completionLoop() {
// 1. 上下文大小检查
// 获取模型的最大上下文大小
uint32_t contextSize = llama_n_ctx(_ctx);
// 获取当前 KV 缓存中已使用的位置(即已处理的 Token 数量)
// llama_memory_seq_pos_max(..., 0) 获取序列 0 的最大位置
_nCtxUsed = llama_memory_seq_pos_max(llama_get_memory(_ctx), 0) + 1;
// 检查:当前已使用的上下文长度 + 批次中的 Token 数是否超过模型最大上下文
// 如果超过,则抛出运行时错误,停止生成
if (_nCtxUsed + _batch->n_tokens > contextSize) {
throw std::runtime_error("context size reached");
}
// 2. 模型推理
auto start = ggml_time_us(); // 计时开始
// 运行模型解码:执行前向传播,计算当前批次中 Token 的 Logits
// 此时 _batch 中应该只包含上一步采样出的新 Token,并且已设置好位置等信息。
if (llama_decode(_ctx, *_batch) < 0) {
throw std::runtime_error("llama_decode() failed"); // 解码失败
}
// 3. Token 采样和生成结束检查 (Sampling and EOG Check)
// 从最新的 Logits 中采样下一个 Token ID
// -1 表示使用批次中最后一个 Token 的 Logits 进行采样
_currToken = llama_sampler_sample(_sampler, _ctx, -1);
// 检查采样出的 Token 是否是 EOG (End of Generation) 标记
if (llama_vocab_is_eog(llama_model_get_vocab(_model), _currToken)) {
// 如果是 EOG,则将完整的回复添加到聊天记录中
addChatMessage(strdup(_response.data()), "assistant");
_response.clear();
return "[EOG]"; // 返回特殊标记表示生成结束
}
// 将 Token ID 转换为可读的文本片段 (word-piece)
std::string piece = common_token_to_piece(_ctx, _currToken, true);
// 4. 性能记录和缓存 略
...
// 5. 为下一轮循环准备
// 重新初始化批次:为下一次 llama_decode 准备输入数据
// 下一次解码只需要处理这一个新生成的 Token
_batch->token = &_currToken; // 将批次的 Token 指针指向新生成的 Token ID
_batch->n_tokens = 1; // 设置批次中只有一个 Token
// **注意:** 在下一个循环中,这个 `_batch` 中的 Token 将会被 `llama_decode` 处理,
// 其位置信息等需要在使用前被更新 (通常由 llama_decode 内部处理或在一个辅助函数中完成)。
//
// token有效性检查,检查缓存的 Token 片段是否是一个有效的 UTF-8 序列
if (_isValidUtf8(_cacheResponseTokens.c_str())) {
// 如果有效, 将有效片段添加到完整的回复中
_response += _cacheResponseTokens;
// 拷贝有效片段用于返回
std::string valid_utf8_piece = _cacheResponseTokens;
// 清空缓存,等待下一个 Token
_cacheResponseTokens.clear();
// 在这里返回完整的 UTF-8 文本片段
return valid_utf8_piece;
}
// 如果无效,返回空字符串
return "";
}
这个函数结合了 模型推理(llama_decode)、Token 采样(llama_sampler_sample)、生成停止检查和 UTF-8 编码处理 ,是实现流式输出的关键。
下一层核心的方法为 llama_decode 和 llama_sampler_sample 函数。
llama_decode
llama_context::decode 是 llama.cpp 中负责执行模型前向传播(即推理)的核心函数。它将一个批次的输入 Token(存储在 llama_batch 中)转化为模型的输出(Logits 或嵌入向量),并同时管理模型的 KV 缓存。
/**
* @brief 执行模型解码(前向传播)。将输入的 Token 批次通过模型进行计算。
* @return 0 成功;-1 失败;-2 内存/计算错误;1 KV 缓存不足但已尝试优化;2 被取消。
*/
int llama_context::decode(const llama_batch & batch_inp)
这个函数可以大致分为以下几个核心阶段:
- 输入验证和初始化: 检查输入批次是否有效,处理特殊情况。
- KV 缓存管理: 核心步骤,决定如何将批次中的 Token 放入 KV 缓存。
- 子批次循环 (UBatch Loop): 如果批次太大,将其分解为适合内存的小块进行处理。
- 计算图构建与执行: 为每个子批次构建并执行模型计算图(Transformer Layers)。
- 结果提取: 将计算结果(Logits 和/或嵌入向量)从设备内存异步传输回 CPU 内存。
- 输出排序与映射: 确保输出结果的顺序与用户的输入顺序一致。
llama_sampler_sample
llama_sampler_sample 函数是 llama.cpp 中负责从模型输出中选出下一个 Token 的函数,即执行 Token 采样 的过程。
它的作用是将模型计算出的原始概率(Logits)转换为一个具体的、用于文本生成的新 Token ID。
这个函数可以分解为以下几个关键步骤:
llama_token llama_sampler_sample(struct llama_sampler * smpl, struct llama_context * ctx, int32_t idx) {
// 1. 获取 Logits 和模型信息
// 从上下文中获取指定索引位置的 Logits 数组
const auto * logits = llama_get_logits_ith(ctx, idx);
const llama_model * model = llama_get_model(ctx);
const llama_vocab * vocab = llama_model_get_vocab(model);
// 获取词汇表大小
const int n_vocab = llama_vocab_n_tokens(vocab);
// 2. 构建 Token 候选列表
// 创建一个临时的 std::vector 用于存储所有 Token 的数据结构
// TODO: 考虑优化,避免每次采样都重新分配内存
std::vector<llama_token_data> cur;
cur.reserve(n_vocab);
// 遍历整个词汇表,将每个 Token ID 及其对应的 Logits 值打包成 llama_token_data 结构
for (llama_token token_id = 0; token_id < n_vocab; token_id++) {
// llama_token_data 结构体包含 ID, Logits 和概率 (prob,这里初始化为 0.0f)
cur.emplace_back(llama_token_data{token_id, logits[token_id], 0.0f});
}
// 将 std::vector 包装成 llama_token_data_array 结构,这是采样链的标准输入格式
llama_token_data_array cur_p = {
/* .data = */ cur.data(), // 指向数据数组
/* .size = */ cur.size(), // 数组大小 (词汇表大小)
/* .selected = */ -1, // 初始化为 -1 (未选择)
/* .sorted = */ false, // 尚未排序
};
// 3. 应用采样链
// 调用核心采样函数:遍历 smpl 中配置的所有采样策略(如 Logits 惩罚、Top-K、Top-P、Temperature)
// 这个函数会修改 cur_p.data 中的 Logits 值,并最终在 cur_p.selected 中标记选中的 Token 索引
llama_sampler_apply(smpl, &cur_p);
// 4. 提取和接受 Token
// 断言检查:确保采样器已经成功选择了一个有效的 Token
GGML_ASSERT(cur_p.selected >= 0 && cur_p.selected < (int32_t) cur_p.size);
// 从选中的索引位置提取最终的 Token ID
auto token = cur_p.data[cur_p.selected].id;
// 通知采样器:这个 Token 已经被选中并使用。
// 这允许采样器更新内部状态,例如:
// - 更新上次生成的 Token 列表,以便在下一轮应用重复惩罚 (Repetition Penalty)。
llama_sampler_accept(smpl, token);
// 返回最终选出的 Token ID
return token;
}
返回阶段性推理结果
模型的前向推理和采样完成之后,最后一步就是结合模型的词汇表。转换为可读的string字符串数据:
std::string common_token_to_piece(const struct llama_context * ctx, llama_token token, bool special) {
const llama_model * model = llama_get_model(ctx);
const llama_vocab * vocab = llama_model_get_vocab(model);
return common_token_to_piece(vocab, token, special);
}
对于Java层,可以通过token数量,或者检测返回的token中是否有 “EOG” 字符串。即 End Of Generation 。当模型采样到一个被词汇表 (llama_vocab) 识别为 EOG 的 Token ID 时,意味着模型认为它已经完成了对用户 Prompt 的回答。
// sample a token and check if it is an EOG (end of generation token)
_currToken = llama_sampler_sample(_sampler, _ctx, -1);
if (llama_vocab_is_eog(llama_model_get_vocab(_model), _currToken)) {
// ... 返回 "[EOG]" 停止生成 ...
}
运行效果
将这个模组直接封装成一个aar,也可以直接被其他模组依赖编译。
外部使用时,先将 .gguf 文件从手机下载路径复制到内部目录,也可以直接在线从 Hugging Face 上下载到本地内部目录。然后调用 loadModel() 、 getResponseAsFlow() 等接口来加载模型,获取生成的对话回复。
运行结果如下,模型加载和对话回复:
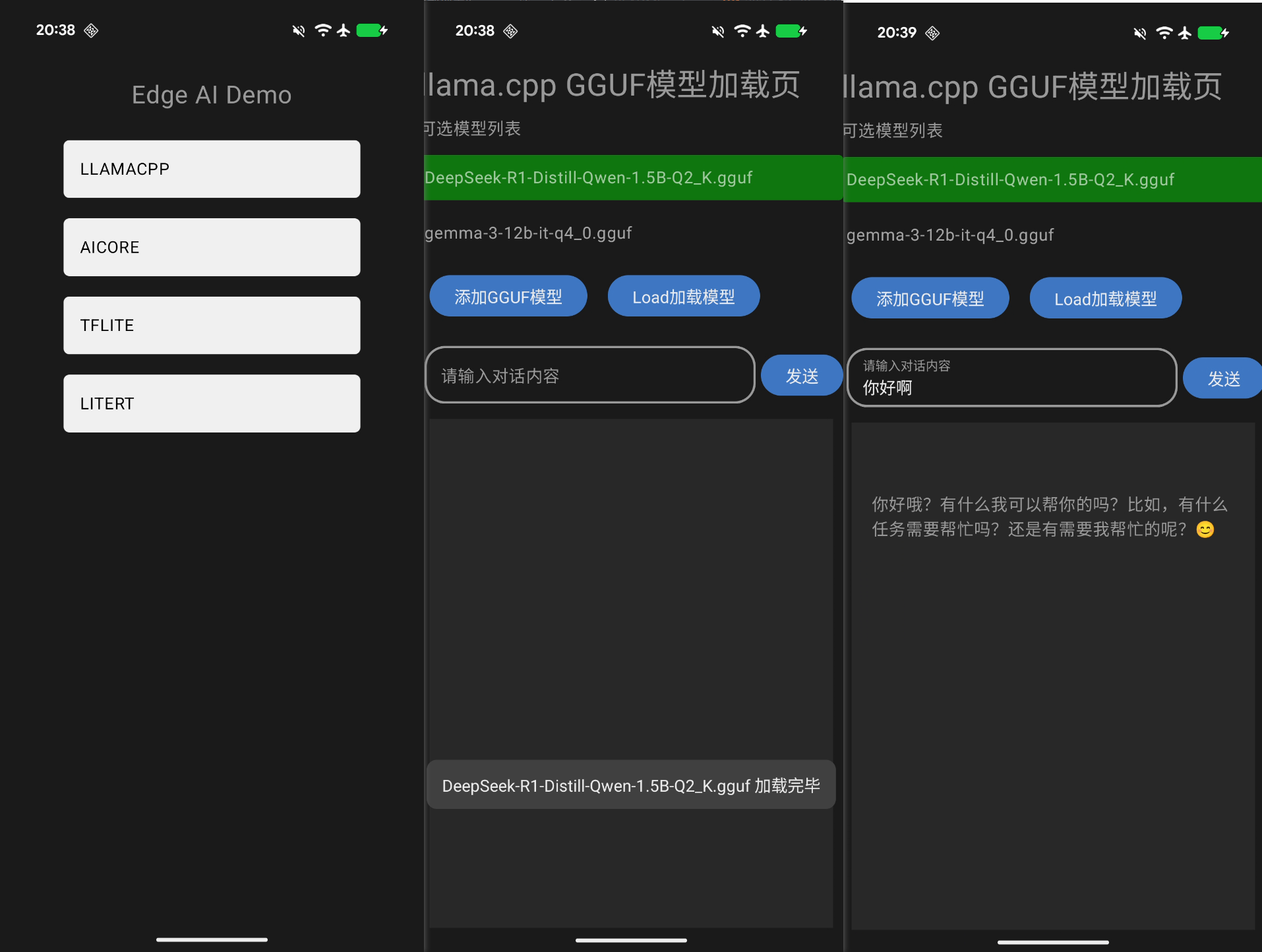
打开实时的片段生成和性能追踪对比。推理过程的打印日志如下:
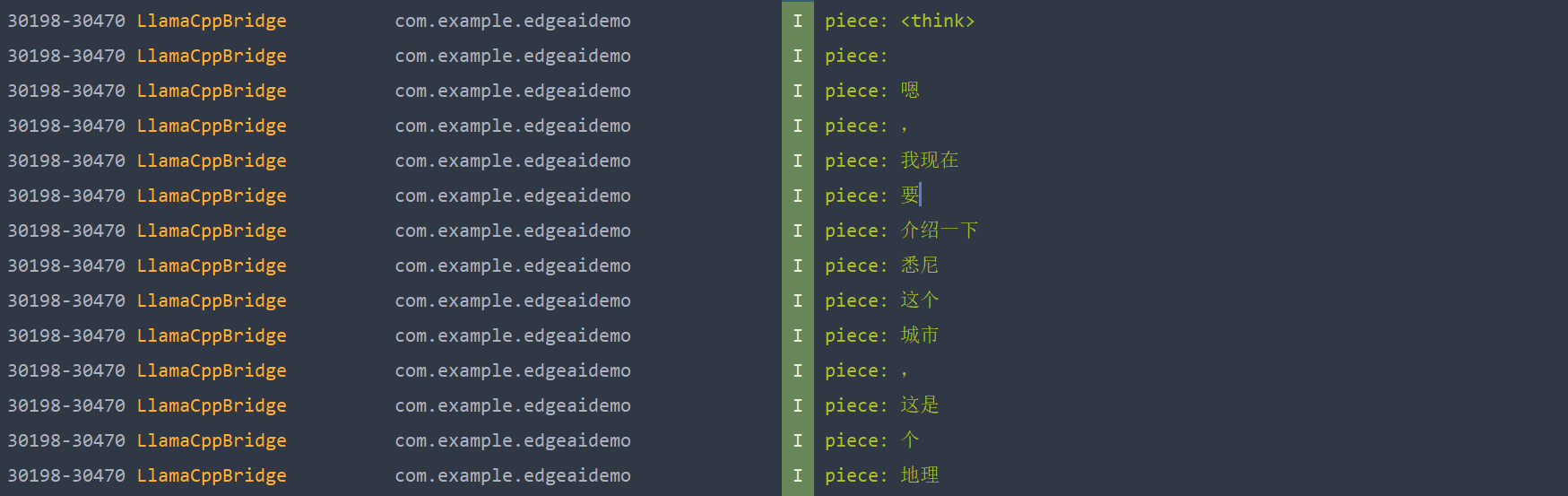
使用 Android Studio 的 Profiler ,实时性能监控:
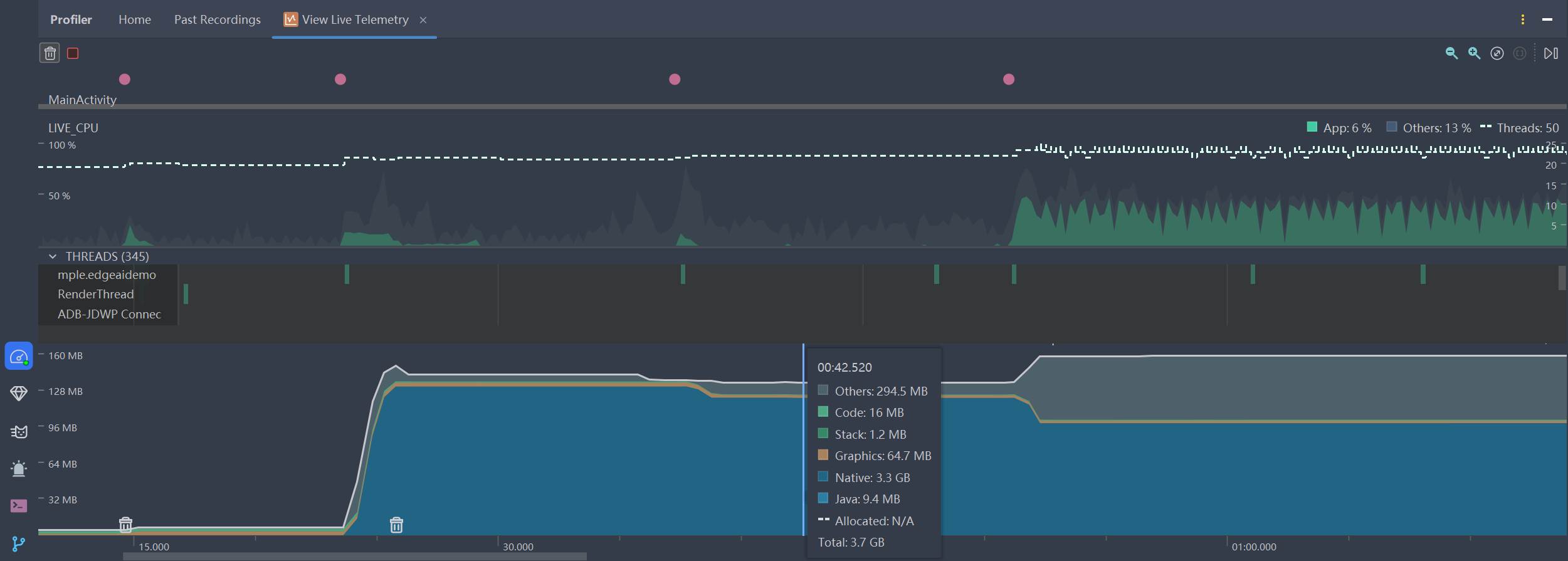
在加载模型是有一段巨大的爬升,将整个模型包括权重数据都对应读取到了 Native 堆中等待使用。在推理时可以看到CPU是程锯齿状一段一段地起伏,说明LLM正在执行一轮一轮的 自回归生成 。
多模态展望
在5个月前,llama.cpp已经启动多模态的集成开发,仅支持llama-server的模式启动,目前还没有尝试使用JNI的模式集成到app内,待有空了再研究下图像和音频的处理。